

Build a Scalable Remote Code Execution Engine in Under 500 lines of Code
Exploring the architecture and code for a cloud-native code execution system with request-level resource limits and isolation.

Motivation
A few years ago, inspired by Crafting Interpreters by Robert Nystrom, I developed a compiler for a toy programming language called Tok. This project, spanning several months, helped me peek under the hood and understand how programming languages are designed, and how compilers are built.

Despite the effort, the compiler has remained mostly unused, tucked away in a GitHub repository. The only way for anyone to use it has been to clone the repository and build the compiler from the source—an effort I recognize is too cumbersome for just trying out a new tool (and I've admittedly been too lazy to provide a binary release).
Recently, I decided to do something about this and tried to build an online platform that allows users to write and execute Tok code directly in their web browser. The code is executed remotely in the cloud, and results are returned to the user. In addition to making Tok more accessible, this effort allowed me to learn a few new things that I plan to share in this issue.
Challenges
Setting up a server on an EC2 instance to compile and execute incoming code is straightforward. However, there are several critical things we need to think about:
Scalability: How do we handle potentially thousands of concurrent requests? Is it easy to scale up resources to meet user demand?
Resource Management: How can we ensure that a single heavy request does not monopolize system resources and degrade performance for other users?
Security and Isolation: Given that we're executing user-provided code, it is crucial to execute each piece of code in a fully isolated environment. This isolation helps prevent unauthorized access to the host machine and secures the system against malicious attacks.
Latency Optimization: How do we minimize response times for each request?
Architecture
Our system is designed as a cloud-native application, which can naturally scale with increasing load.
We'll use Kubernetes to orchestrate the various services, all of which will be implemented in Go.

Our system will consist of a Coordinator service which performs authentication, authorization, rate limiting, and other auxiliary tasks, and a Code Execution Service which runs the code.
Code Execution Service
At the core of our system lies the code execution service, which runs incoming code and returns the results. This service consists of a ClusterIP, which acts as a load balancer for all numerous code executor replicas behind it. The ClusterIP distributes requests across these replicas and is only accessible internally within the cluster—not exposed to the internet.
You may be wondering why we have a separate coordinator service, when k8s already provides us a load balancer. Is it not easier to put all the code executors directly behind a public load balancer, and let them handle authentication? Adding a few additional lines of code to the executor is surely better than having to manage an entirely separate coordinator service, right?
To answer this you must understand that rate-limiting, authentication, and such services will often talk to databases and other external services. The code executors are designed to scale up with increasing load, and it is possible for us to have a few thousand executors running at peak hours. This would mean each of these executors will have to maintain its own database connection. A few thousand open connections are enough to bog down the database, and potentially take the entire service offline.
It is much safer to keep this logic inside a coordinator service, which consists of fewer replicas and therefore creates fewer database connections.
Each code executor is a simple Go server set up to process the code it receives. As previously highlighted, executing this code in a secure and resource-constrained manner is important. To achieve this, we run compile and execute each request within its own docker container. This container should have everything required to compile and execute the code.
Note: we use code-executor and compiler-server interchangeably in this article.
Compiler Container
Each request spins up a compiler to execute code, to minimize the container startup time, the compiler Docker image must be as lightweight as possible. Our approach involves using a multi-stage Dockerfile to build the image efficiently.
Consider the following Dockerfile for the compiler:
![# Use an official base image with C++ and CMake installed FROM --platform=linux/amd64 ubuntu:20.04 as builder ARG DEBIAN_FRONTEND=noninteractive # Install necessary packages RUN apt-get update && \ apt-get install -y git build-essential software-properties-common lsb-release wget # Install latest CMake from Kitware RUN wget -O - https://apt.kitware.com/keys/kitware-archive-latest.asc \ | gpg --dearmor - > /usr/share/keyrings/kitware-archive-keyring.gpg RUN echo "deb [signed-by=/usr/share/keyrings/kitware-archive-keyring.gpg] \ https://apt.kitware.com/ubuntu/ $(lsb_release -cs) main" | \ tee /etc/apt/sources.list.d/kitware.list >/dev/null RUN apt-get update && apt-get install -y cmake # Clone the repository and build the project RUN git clone https://github.com/JyotinderSingh/ctok.git /ctok && \ mkdir /ctok/build && \ cd /ctok/build && \ cmake -DCMAKE_BUILD_TYPE=Release -DBUILD_SHARED_LIBS=OFF -DCMAKE_EXE_LINKER_FLAGS="-static" .. && \ cmake --build . RUN chmod +x /ctok/build/ctok # Create an alpine image with the built object FROM --platform=linux/amd64 alpine:latest # Set the Current Working Directory inside the container WORKDIR / # Copy the statically linked binary from the builder stage COPY --from=builder /ctok/build/ctok /ctok # Command to run the binary CMD ["/ctok"]](https://substackcdn.com/image/fetch/$s_!n5f-!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fe27627c3-9095-48bd-aeab-6633ab66c6c7_3859x3372.png "# Use an official base image with C++ and CMake installed FROM --platform=linux/amd64 ubuntu:20.04 as builder ARG DEBIAN_FRONTEND=noninteractive # Install necessary packages RUN apt-get update && \ apt-get install -y git build-essential software-properties-common lsb-release wget # Install latest CMake from Kitware RUN wget -O - https://apt.kitware.com/keys/kitware-archive-latest.asc \ | gpg --dearmor - > /usr/share/keyrings/kitware-archive-keyring.gpg RUN echo \"deb [signed-by=/usr/share/keyrings/kitware-archive-keyring.gpg] \ https://apt.kitware.com/ubuntu/ $(lsb_release -cs) main\" | \ tee /etc/apt/sources.list.d/kitware.list >/dev/null RUN apt-get update && apt-get install -y cmake # Clone the repository and build the project RUN git clone https://github.com/JyotinderSingh/ctok.git /ctok && \ mkdir /ctok/build && \ cd /ctok/build && \ cmake -DCMAKE_BUILD_TYPE=Release -DBUILD_SHARED_LIBS=OFF -DCMAKE_EXE_LINKER_FLAGS=\"-static\" .. && \ cmake --build . RUN chmod +x /ctok/build/ctok # Create an alpine image with the built object FROM --platform=linux/amd64 alpine:latest # Set the Current Working Directory inside the container WORKDIR / # Copy the statically linked binary from the builder stage COPY --from=builder /ctok/build/ctok /ctok # Command to run the binary CMD [\"/ctok\"]")
This is a multi-stage Dockerfile to build our image.
The first stage of our Dockerfile uses
ubuntu:20.04as the base. Here, we install CMake along with essential build tools. We then clone thectokrepository—our Tok compiler written in C—and use CMake to compile the source into a binary.In the second stage, we shift to a minimal
alpinebase image, approximately 8MB in size, where we copy over the binary from the first stage. This method ensures that the final image contains only the necessary executable and its dependencies, omitting all the build-specific tools and libraries, thus significantly reducing the image size.
Since I am building these images on a Mac, I use the platform=linux/amd64 flag with each base image to ensure compatibility with the cloud environments.
I use the following commands to build and push this image to Docker hub.
$ docker build -t jyotindersingh/ctok .
$ docker push jyotindersingh/ctokCompiler Server (code executor)
![package main import ( "context" "io" "log" "net/http" "os" "os/exec" "path/filepath" "time" ) const ( serverPort = ":8080" compilerImage = "jyotindersingh/ctok" maxCodeSize = 1024 * 1024 // 1 MB executionTimeout = 5 * time.Second // 5 seconds ) func main() { http.HandleFunc("/", compileAndRunCodeHandler) log.Fatal(http.ListenAndServe(serverPort, nil)) } func compileAndRunCodeHandler(w http.ResponseWriter, r *http.Request) { if r.ContentLength > maxCodeSize { http.Error(w, "Code size is too large", http.StatusBadRequest) return } code, err := io.ReadAll(r.Body) if err != nil { handleError(w, "Failed to read request body", err) return } output, err := compileAndRunCode(code) if err != nil { handleError(w, "Compilation or execution failed: "+string(output), err) return } w.Write(output) } func compileAndRunCode(code []byte) ([]byte, error) { tmpFile, err := os.CreateTemp("", "code-*.tok") if err != nil { return nil, err } defer os.Remove(tmpFile.Name()) if err := os.WriteFile(tmpFile.Name(), code, 0666); err != nil { return nil, err } absPath, err := filepath.Abs(tmpFile.Name()) if err != nil { return nil, err } // Create a context with the defined timeout ctx, cancel := context.WithTimeout(context.Background(), executionTimeout) defer cancel() cmd := exec.CommandContext(ctx, "docker", "run", "--platform", "linux/x86_64", "--rm", "-i", "-m", "65m", "--cpus", "0.1", "-v", absPath+":"+absPath, compilerImage, "/ctok", absPath) log.Printf("Running command: %s; with code: %s", cmd.String(), code) output, err := cmd.CombinedOutput() if err != nil { return output, err } return output, nil } func handleError(w http.ResponseWriter, msg string, err error) { log.Printf("%s: %v", msg, err) http.Error(w, msg+": "+err.Error(), http.StatusInternalServerError) }](https://substackcdn.com/image/fetch/$s_!jTR3!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fcda5bb11-7792-4f73-a330-8a668537d6e3_3035x7404.png "package main import ( \"context\" \"io\" \"log\" \"net/http\" \"os\" \"os/exec\" \"path/filepath\" \"time\" ) const ( serverPort = \":8080\" compilerImage = \"jyotindersingh/ctok\" maxCodeSize = 1024 * 1024 // 1 MB executionTimeout = 5 * time.Second // 5 seconds ) func main() { http.HandleFunc(\"/\", compileAndRunCodeHandler) log.Fatal(http.ListenAndServe(serverPort, nil)) } func compileAndRunCodeHandler(w http.ResponseWriter, r *http.Request) { if r.ContentLength > maxCodeSize { http.Error(w, \"Code size is too large\", http.StatusBadRequest) return } code, err := io.ReadAll(r.Body) if err != nil { handleError(w, \"Failed to read request body\", err) return } output, err := compileAndRunCode(code) if err != nil { handleError(w, \"Compilation or execution failed: \"+string(output), err) return } w.Write(output) } func compileAndRunCode(code []byte) ([]byte, error) { tmpFile, err := os.CreateTemp(\"\", \"code-*.tok\") if err != nil { return nil, err } defer os.Remove(tmpFile.Name()) if err := os.WriteFile(tmpFile.Name(), code, 0666); err != nil { return nil, err } absPath, err := filepath.Abs(tmpFile.Name()) if err != nil { return nil, err } // Create a context with the defined timeout ctx, cancel := context.WithTimeout(context.Background(), executionTimeout) defer cancel() cmd := exec.CommandContext(ctx, \"docker\", \"run\", \"--platform\", \"linux/x86_64\", \"--rm\", \"-i\", \"-m\", \"65m\", \"--cpus\", \"0.1\", \"-v\", absPath+\":\"+absPath, compilerImage, \"/ctok\", absPath) log.Printf(\"Running command: %s; with code: %s\", cmd.String(), code) output, err := cmd.CombinedOutput() if err != nil { return output, err } return output, nil } func handleError(w http.ResponseWriter, msg string, err error) { log.Printf(\"%s: %v\", msg, err) http.Error(w, msg+\": \"+err.Error(), http.StatusInternalServerError) }")
The compiler-server represents our code executor. It is a lightweight server listening on port :8080. Upon receiving a request to execute code, it performs initial validations and safety checks, then hands off the code as a string to the compileAndRunCode utility.
This method does a few things:
Creates a temporary file to store the code (by default this file exists inside the
/tmp/*directory of the container).Utilizing the lightweight Compiler Docker compiler image previously created, it spins up a Docker container with specific resource limits set (
"-m 65m --cpus 0.1").The server also attaches a context to the container launch command, with a 5-second timeout. This ensures that no piece of code can end up running indefinitely.
This container uses a bind-mount to access the temporary file (
"-v /tmp/tmp-code.tok:/tmp/tmp-code.tok").
Understanding bind-mounts
A bind mount links a file or directory from the host machine to a container, using its absolute path. This is crucial because our setup involves a Docker in Docker configuration where the compiler container runs within another container hosted by a Kubernetes pod. Due to this nesting, the inner compiler container might not locate the temporary file on the host machine's filesystem since it's effectively looking in the wrong place (the compiler-server container creates the temporary file, but this file doesn’t exist at the same location inside the host machine of the pod).
To address this, we must ensure that the outer container (compiler-server) and the inner compiler container share a bind-mounted volume on the host machine. This shared volume means both containers can access the file seamlessly, despite the nested Docker setup.
The bind mount created in this step is half of the story, we will need to create a bind mount to the same shared directory when we launch the code executor pod in the upcoming sections.
Finally, we containerize this server using the following docker image:
![FROM --platform=linux/amd64 golang:1.21-bookworm as builder # Set the Current Working Directory inside the container WORKDIR /app # Copy the source code into the container COPY . . # Build the Go app RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -o /compiler-server ./server.go # Start a new stage from scratch FROM --platform=linux/amd64 docker:26.1.0-dind # Set the Current Working Directory inside the container WORKDIR / # Import the user and group files from the builder COPY --from=builder /etc/passwd /etc/passwd COPY --from=builder /etc/group /etc/group # Copy the Pre-built binary file from the previous stage COPY --from=builder /compiler-server . # Expose the port the server will run on EXPOSE 8080 # Command to run the executable CMD ["/compiler-server"]](https://substackcdn.com/image/fetch/$s_!hZAp!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fb7f77d77-2852-4cb9-96e3-bb407f194094_3107x2784.png "FROM --platform=linux/amd64 golang:1.21-bookworm as builder # Set the Current Working Directory inside the container WORKDIR /app # Copy the source code into the container COPY . . # Build the Go app RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -o /compiler-server ./server.go # Start a new stage from scratch FROM --platform=linux/amd64 docker:26.1.0-dind # Set the Current Working Directory inside the container WORKDIR / # Import the user and group files from the builder COPY --from=builder /etc/passwd /etc/passwd COPY --from=builder /etc/group /etc/group # Copy the Pre-built binary file from the previous stage COPY --from=builder /compiler-server . # Expose the port the server will run on EXPOSE 8080 # Command to run the executable CMD [\"/compiler-server\"]")
As before, we have a multi-stage docker image. The first stage compiles the Go server into an executable binary. The second stage places it into a Docker in Docker Linux image capable of spinning up nested Docker containers.
I use the following commands to build and push this image to Docker hub.
$ docker build -t jyotindersingh/compiler-server .
$ docker push jyotindersingh/compiler-serverKubernetes Setup
We will define two pieces of infrastructure:
code-execution-deployment: This deployment manages the replicas of our compiler-server containers, ensuring high availability and fault tolerance.code-execution-service: A ClusterIP service that performs load balancing across the compiler-server replicas.
code-execution-deployment

This deployment configuration has a few important details:
replicas: This setting determines the number of compiler-server instances we want running, with each instance operating in its own Kubernetes pod.volumeMounts: We use shared volumes to facilitate the interaction between the nested containers. As we’ve implemented previously, the inner compiler container bind-mounts the/tmp/directory. We replicate this configuration for the outer compiler-server container. Additionally, the host machine’s Docker socket is mounted into the compiler-server container. This setup is crucial for spawning new Docker containers within the compiler-server.
Security and Resource Access: Typically, mounting the host’s Docker socket within a container is not advisable as it can grant the nested containers access to the host’s resources, circumventing the resource constraints imposed by the outer container.
Alternative Approaches: The preferred method would be to run the Docker-in-Docker container in
privilegedmode rather than mounting the Docker socket. This approach can potentially offer better isolation and security. I've encountered challenges with this method, however, I encourage experimenting with it to possibly refine and secure the setup.
code-execution-service

This configuration defines a ClusterIP with an open :8080 port available inside the cluster.
Coordinator Service
![package main import ( "bytes" "fmt" "io" "log" "net/http" "time" ) const ( serverAddress = ":8080" codeExecutionServiceURL = "http://code-execution-service:8080" requestTimeout = 10 * time.Second contentType = "text/plain" ) func main() { http.HandleFunc("/execute", executeCodeHandler) log.Println("Server started on", serverAddress) log.Fatal(http.ListenAndServe(serverAddress, nil)) } // executeCodeHandler handles the /execute endpoint. func executeCodeHandler(w http.ResponseWriter, r *http.Request) { if r.Method != http.MethodPost { http.Error(w, "Only POST method is accepted", http.StatusMethodNotAllowed) return } body, err := io.ReadAll(r.Body) if err != nil { http.Error(w, "Failed to read request body", http.StatusInternalServerError) return } response, err := executeCode(body) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } fmt.Fprintf(w, "Output: %s", response) } // executeCode sends the code to the code execution service and returns the output. func executeCode(code []byte) ([]byte, error) { req, err := http.NewRequest(http.MethodPost, codeExecutionServiceURL, bytes.NewBuffer(code)) if err != nil { return nil, fmt.Errorf("failed to create request to code execution service: %v", err) } req.Header.Set("Content-Type", contentType) httpClient := &http.Client{Timeout: requestTimeout} resp, err := httpClient.Do(req) if err != nil { return nil, fmt.Errorf("failed to send request to code execution service: %v", err) } defer resp.Body.Close() if resp.StatusCode != http.StatusOK { // Read the response body for additional error information errorMsg, err := io.ReadAll(resp.Body) if err != nil { return nil, fmt.Errorf("failed to read error response from execution service: %v", err) } return nil, fmt.Errorf("execution service returned error %d: %s", resp.StatusCode, errorMsg) } output, err := io.ReadAll(resp.Body) if err != nil { return nil, fmt.Errorf("failed to read response body: %v", err) } return output, nil }](https://substackcdn.com/image/fetch/$s_!KAU6!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F6cf2b0d1-c7aa-4f8f-92a1-9cf5acefcdea_3608x6900.png "package main import ( \"bytes\" \"fmt\" \"io\" \"log\" \"net/http\" \"time\" ) const ( serverAddress = \":8080\" codeExecutionServiceURL = \"http://code-execution-service:8080\" requestTimeout = 10 * time.Second contentType = \"text/plain\" ) func main() { http.HandleFunc(\"/execute\", executeCodeHandler) log.Println(\"Server started on\", serverAddress) log.Fatal(http.ListenAndServe(serverAddress, nil)) } // executeCodeHandler handles the /execute endpoint. func executeCodeHandler(w http.ResponseWriter, r *http.Request) { if r.Method != http.MethodPost { http.Error(w, \"Only POST method is accepted\", http.StatusMethodNotAllowed) return } body, err := io.ReadAll(r.Body) if err != nil { http.Error(w, \"Failed to read request body\", http.StatusInternalServerError) return } response, err := executeCode(body) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } fmt.Fprintf(w, \"Output: %s\", response) } // executeCode sends the code to the code execution service and returns the output. func executeCode(code []byte) ([]byte, error) { req, err := http.NewRequest(http.MethodPost, codeExecutionServiceURL, bytes.NewBuffer(code)) if err != nil { return nil, fmt.Errorf(\"failed to create request to code execution service: %v\", err) } req.Header.Set(\"Content-Type\", contentType) httpClient := &http.Client{Timeout: requestTimeout} resp, err := httpClient.Do(req) if err != nil { return nil, fmt.Errorf(\"failed to send request to code execution service: %v\", err) } defer resp.Body.Close() if resp.StatusCode != http.StatusOK { // Read the response body for additional error information errorMsg, err := io.ReadAll(resp.Body) if err != nil { return nil, fmt.Errorf(\"failed to read error response from execution service: %v\", err) } return nil, fmt.Errorf(\"execution service returned error %d: %s\", resp.StatusCode, errorMsg) } output, err := io.ReadAll(resp.Body) if err != nil { return nil, fmt.Errorf(\"failed to read response body: %v\", err) } return output, nil }")
The coordinator a simple passthrough service, which accepts requests from users and forwards them to the code-execution-service.
If you want to add auth, rate-limiting, and other auxiliary features - this is where they should be added.
Dockerfile
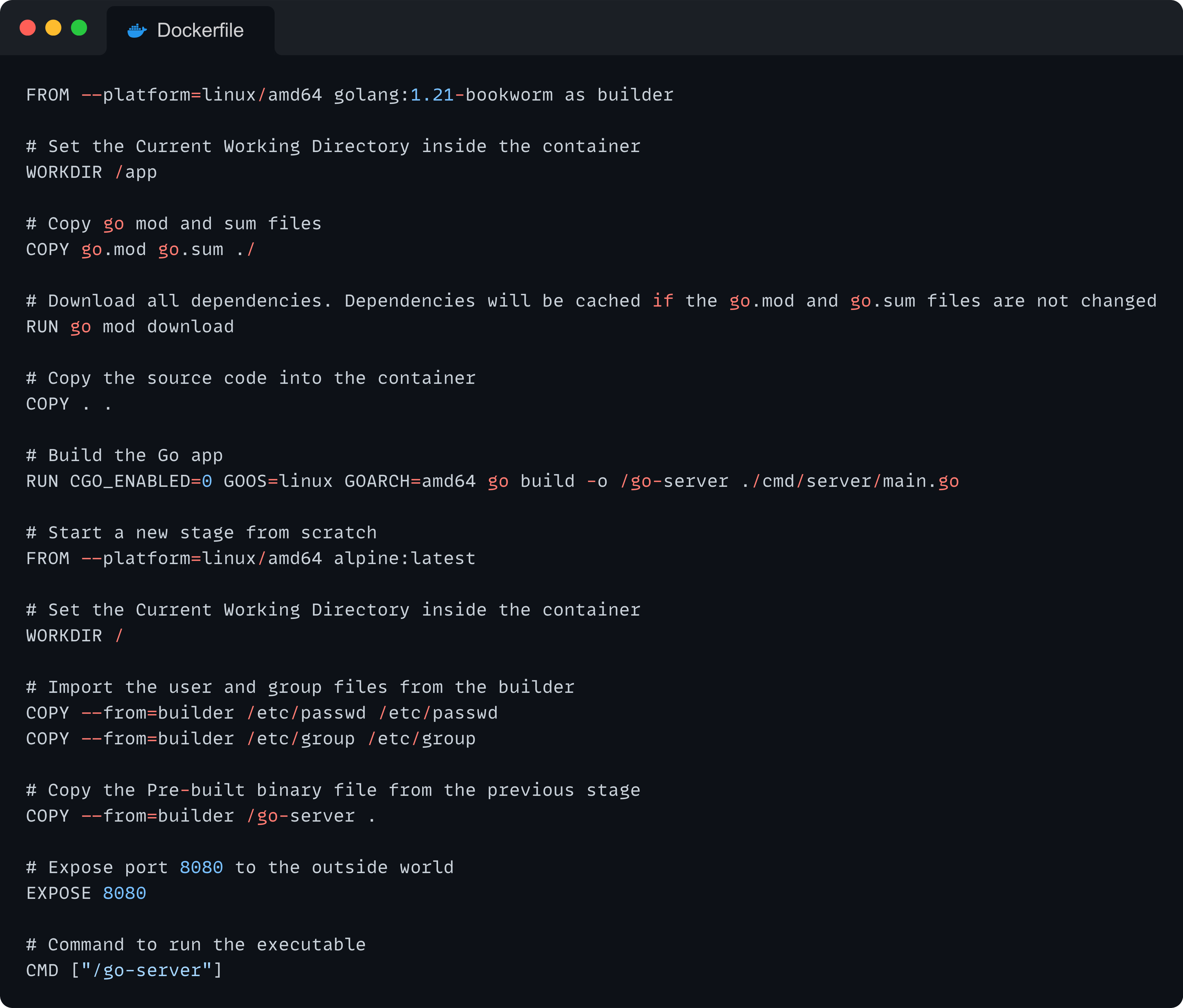
The Docker image builds the server and then copies it into a lightweight alpine image.
I use the following commands to build and push this image to Docker hub.
$ docker build -t jyotindersingh/compiler-coordinator .
$ docker push jyotindersingh/compiler-coordinatorKubernetes Setup
We define two infrastructure components:
coordinator-deployment: This deployment manages the replicas of our coordinator containers, ensuring high availability and fault tolerance.coordinator-service: A ClusterIP service that performs load balancing across the compiler-server replicas.
coordinator-deployment

coordinator-service

The coordinator-service defines a simple LoadBalancer, which users can make requests to.
Deployment
You can use minikube to test this setup locally.
minikube startApply the configurations
kubectl apply -f code-execution-depl.yaml
kubectl apply -f code-execution-srv.yaml
kubectl apply -f coordinator-depl.yaml
kubectl apply -f coordinator-srv.yamlGet the externally available IP address for the coordinator service
minikube service coordinator-service --urlCreate a request to the server
curl --location '<ip address>/execute' \
--header 'Content-Type: text/plain' \
--data 'print "Hello, World!";'This should print the following output to your screen
Hello, World!Concluding thoughts
In this issue, we discussed how one can design and implement a horizontally scalable remote code execution service. We also went into the nitty-gritty of sharing files with nested containers, some security considerations, and how to deploy the overall setup to the cloud.
The complete code for this project is available on my GitHub.