

Building a Write-Optimized Database Engine: High Level Architecture (Part 1)
Diving into log-structured storage, the in-memory and on-disk components, and related optimisations.


Preface
In this issue and the ones that follow, we'll explore how log-structured storage systems work and the design choices that enable them to support exceptionally high write throughput while maintaining efficient read performance. By the end of this series, you will have built your own concurrent, write-optimized, and embedded key-value database.
We'll start with an overview of how these systems store data in memory and how they organize it on disk. This issue focuses on the high-level architecture and design principles of a log-structured storage system. In subsequent issues, we'll understand the specifics of each component along with the low-level implementation details.
The goal of this series is to give you a clear understanding along with the practical skills to create a write-optimized storage engine.
Writes, writes, writes

Modern internet-scale applications often produce and ingest huge amounts of data every second. Consider a few examples:
Google ingests stats information (impressions, clicks, etc.) for millions of advertisements on millions of properties across the web.
Instagram stores millions of likes, shares, and messages.
Twitter thread-bois (X-bois?) bookmark every single DSA cheat-sheat and roadmap on their timeline (and proceed to never look at them again.)
The above applications are supported by robust, scalable, and write-optimized data stores. Many of these companies developed in-house technologies to support these needs; Google developed Spanner and LevelDB, Facebook wrote RocksDB, and Twitter made Manhattan.
If you dive into their respective papers, you’ll find the concept of log-structured storage influencing each of their designs. Log-structured storage is the idea of writing data in a sequential, log-like manner. Data once written is usually not modified. Instead of updating data where it already exists, new information, including updates and deletes, gets added to the end as new entries. This means that we usually end up with multiple versions of the same data, and the most recent version, marked by the latest timestamp, is the one that's considered valid.
This strategy takes advantage of the sequential write performance of modern storage hardware significantly reducing write, update, and delete latency. It also simplifies crash recovery since all data is written sequentially and there is a lower chance of corrupting previously written data.
What about B-Trees?
B-trees have been used in database storage engines for a long time. Contrasting the append-only nature of log-structured storage with traditional B-trees (with in-place updates) highlights the trade-offs that each design makes to optimize different aspects of database performance:
B-trees offer better read performance since data is organized in a hierarchical structure and stored in place, once the data is located on the disk, it can be directly returned to the user.
This comes at the expense of write-performance. To update previously written data the system needs to first locate the record on the disk, potentially move data around to keep the tree sorted and balanced, and then perform the update.Append-only storage is optimized for write performance. Updates and new data are simply appended to the end of a log-like structure, eliminating the need to locate and move existing records before writing.
However, this degrades read performance, since operations like range scans may need to fetch multiple copies of the same data and then reconcile them.
Log-Structured Merge Trees
One of the most popular data structures that use log-structured storage to provide efficient handling of write-heavy workloads is the LSM (Log-Structured Merge) Tree. It uses an in-memory buffer and append-only on-disk storage structures to achieve fast sequential writes.
Writes
When receiving writes, instead of directly committing incoming data onto the disk, LSM trees buffer this data in memory in a structure known as the “memtable”. The memtable, which operates as a high-speed write buffer, organizes data in sorted order, using data structures like sorted trees or skip lists to allow efficient writes, updates, and delete operations.
Storing the data in sorted order not only allows fast writes but also efficient reads. In addition to fast key lookups, sorted data also supports efficient range scans.
The data within the memtable remains in memory until a specific flush condition is triggered, usually when the size of the memtable reaches a predetermined threshold. At this point, the contents of the memtable are sequentially flushed to the disk, creating an immutable file known as an SSTable (Sorted String Table). The name Sorted String Table comes from the fact that the data is written to the disk in sorted order (same as the memtable). Since the data is written in sorted order on this disk, the system can make use of a simple binary search algorithm to look up entries.
Additionally, to ensure data integrity and prevent data loss in case of a crash, LSM trees often use a write-ahead log (WAL). Before data is inserted into the memtable, it is first recorded in the WAL. This ensures that even if the system crashes before the memtable is flushed, no data is lost, as the WAL can be replayed during recovery.
I have discussed write-ahead logs in a lot more detail in a previous issue.

Compaction
As write operations come in, data is first accumulated in the memtable and then periodically flushed to disk, resulting in the creation of immutable SSTables. This cycle, while optimizing write performance, leads to the accumulation of multiple versions of the same keys and a growing number of delete markers, known as "Tombstones". These tombstones are special entries that indicate deleted data, which needs to be explicitly recorded as SSTables are immutable, and existing data cannot be directly modified or removed.
This process of continually adding new versions of data and tombstones without directly removing the outdated or deleted entries can cause the physical storage required on the disk to significantly surpass the space needed for the actual, logical dataset. To manage and mitigate this inefficiency, LSM trees implement a crucial process called compaction.
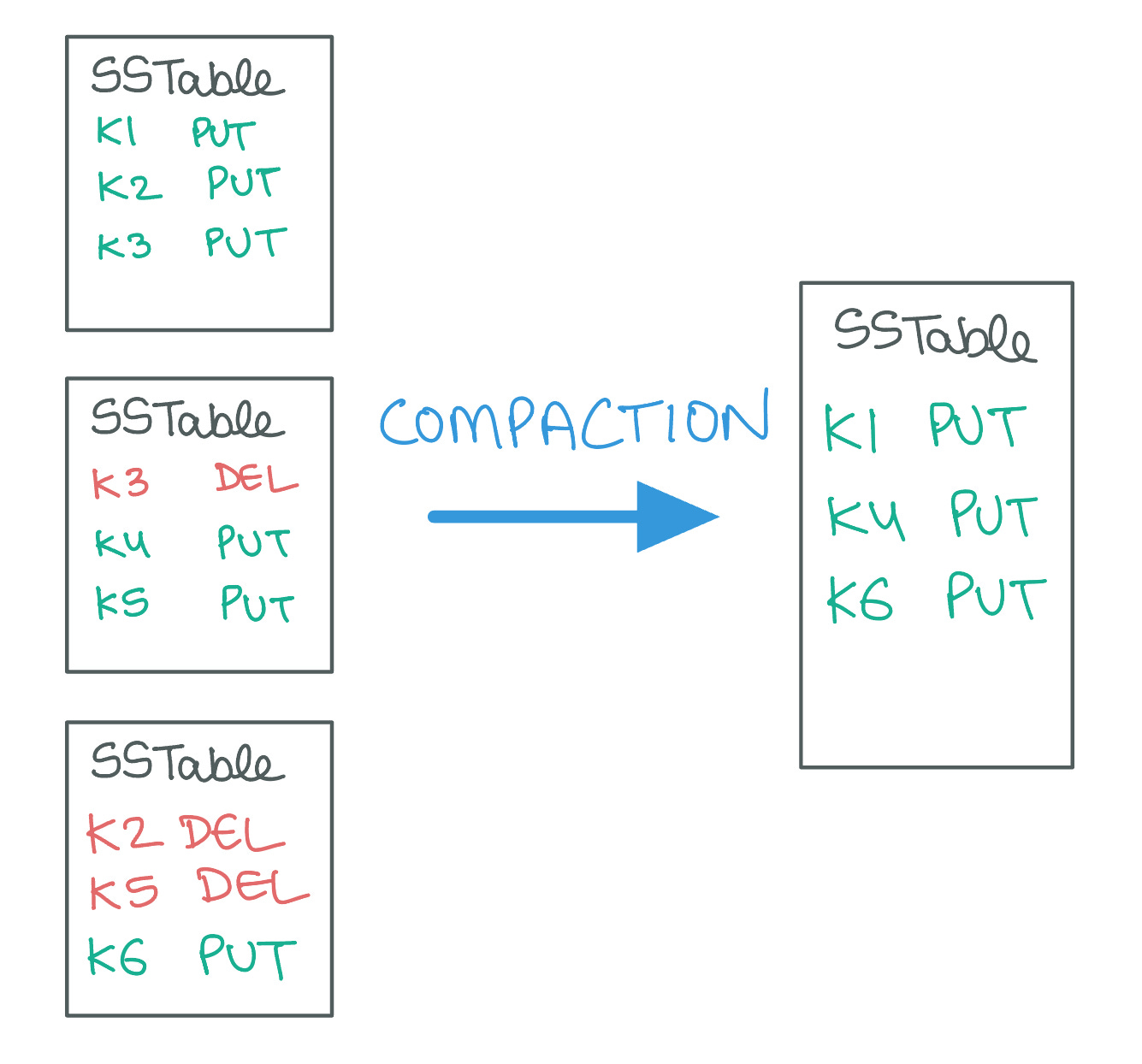
Compaction is the mechanism through which LSM trees consolidate these SSTables, merging multiple tables and their entries to eliminate redundant versions of data and remove entries marked by tombstones. During this process, the system keeps only the latest version of each key. This optimizes storage utilization and improves read performance by reducing the number of SSTables a read operation might need to search through to find the latest value of a key.
There are many different compaction strategies, each optimized for a particular class of workloads. Two of the most famous kinds of compaction strategies are described below.
Level Compaction
Level compaction organizes SSTables into distinct levels. Each level can contain a fixed number of SSTables, except for the first level (L0), which directly receives flushed SSTables from the memtable. As SSTables are compacted and moved from one level to the next, their size increases exponentially. When an SSTable is moved up a level, it is merged with all overlapping SSTables in that level, ensuring that each key exists in only one SSTable per level.
This approach limits the number of SSTables that must be read during a lookup, as each level is guaranteed to have a bounded number of SSTables. The main advantages of level compaction are the more predictable read performance and better space utilization, as it effectively limits duplication of data across levels.
However, it can lead to higher write amplification as data is rewritten multiple times during the compaction process.
Google’s LevelDB uses this compaction strategy, as might be evident from its name.
Tiered Compaction
Tiered compaction also groups SSTables into tiers or levels. When a tier exceeds its capacity in terms of the number of SSTables, those SSTables are merged into a single, larger SSTable, which is then moved to the next tier or level. Unlike level compaction, tiered compaction allows multiple SSTables in a tier to contain the same keys, merging them only when the tier's capacity is exceeded.
This strategy is designed to reduce write amplification by delaying merges and taking advantage of larger, less frequent compactions. This can result in improved write performance but may lead to less efficient space utilization and potentially slower read operations, as more SSTables may need to be checked during data retrieval.
We will be implementing tiered compaction later in this series.
Reads
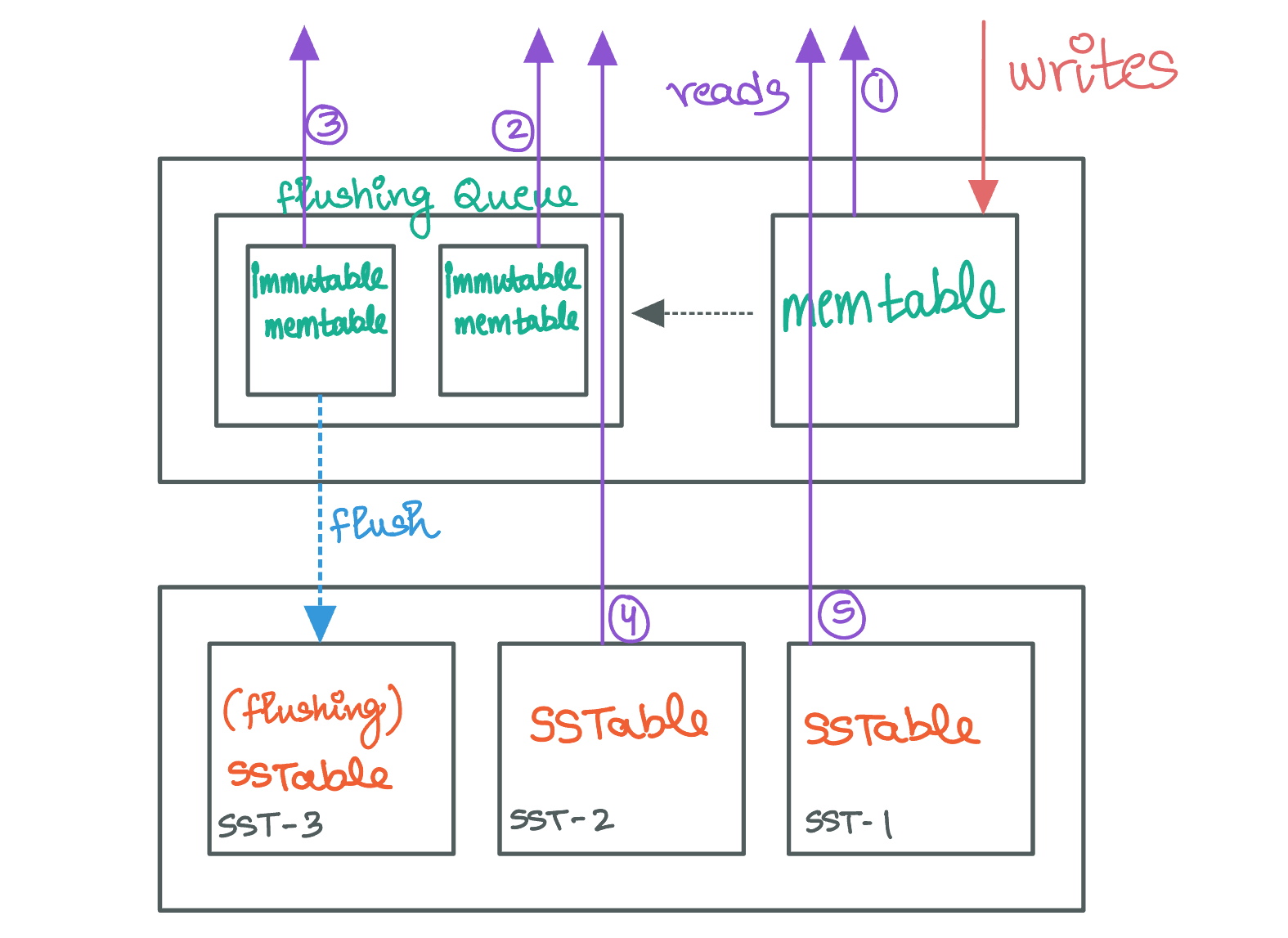
The key-value pairs in an LSM Tree can exist either inside the in-memory component or on one of the on-disk SSTables. Therefore, when a read request needs to be serviced the system usually needs to check multiple components. The system also needs to ensure that the value being returned to the user is the latest one since multiple versions of the same key can be present in the LSM Tree.
We’ll discuss and implement two main kinds of read requests
Point Lookups
When servicing a request to return the value associated with a single key, the system first checks the memtable since it contains the most recent writes. If the key isn't found in the memtable, the system then searches in the most recent SSTable on disk, and if necessary, continues checking older SSTables (from the lowest to the highest level/tier) until the key is found or all SSTables have been searched.
To optimize this process, LSM Trees often use additional structures like bloom filters to quickly determine if an SSTable is likely to contain the key, reducing the need to search SSTables that don't contain the key. We’ll discuss bloom filters in detail in the upcoming issues.
Range Scans
A range scan involves retrieving all key-value pairs within a specified range of keys. This operation starts similarly to a point lookup, with the system scanning the memtable for any keys within the range. However, because range scans cover multiple keys, the system must also search through all the SSTables to compile a complete list of key-value pairs within the range, since different SSTables might contain different keys that satisfy the range filter.
This is more complex than point lookups because it often involves merging overlapping key ranges from different SSTables and filtering out older versions of the keys to ensure that only the latest values are returned.
What’s next?
While the concepts of memtable flushing, SSTable management, and compaction strategies might seem relatively straightforward in theory, implementing them in a concurrent environment is not trivial.
In the upcoming issues, we'll understand how to effectively manage these tasks. We'll explore strategies for handling memtable flushing while still accepting new writes without interruption, performing efficient key lookups within SSTables, and executing SSTable merges and key range reconciliations.
Additionally, we'll examine the use of bloom filters to swiftly exclude irrelevant SSTables during lookups, and how to ensure read operations and range scans remain efficient and accurate even as compaction processes run in the background.
The complete code that we will be working towards is already available on my GitHub in case you would like to dive into it yourself :)
References
Database Internals - Alex Petrov
Designing Data Intensive Applications - Martin Kleppmann
Reading the bit about using write optimised data stores. At what point do write perf requirements make you think about using a log structured storage vs something based on B trees? Any numbers for write throughput etc. that can be used to reason about this?