

Building an Elastic Queuing Service using Kubernetes
How do you build something like SQS with lambda workers without having to learn what an I-Ay-Em policy is

This issue is inspired by an e-lafda among our Western counterparts.
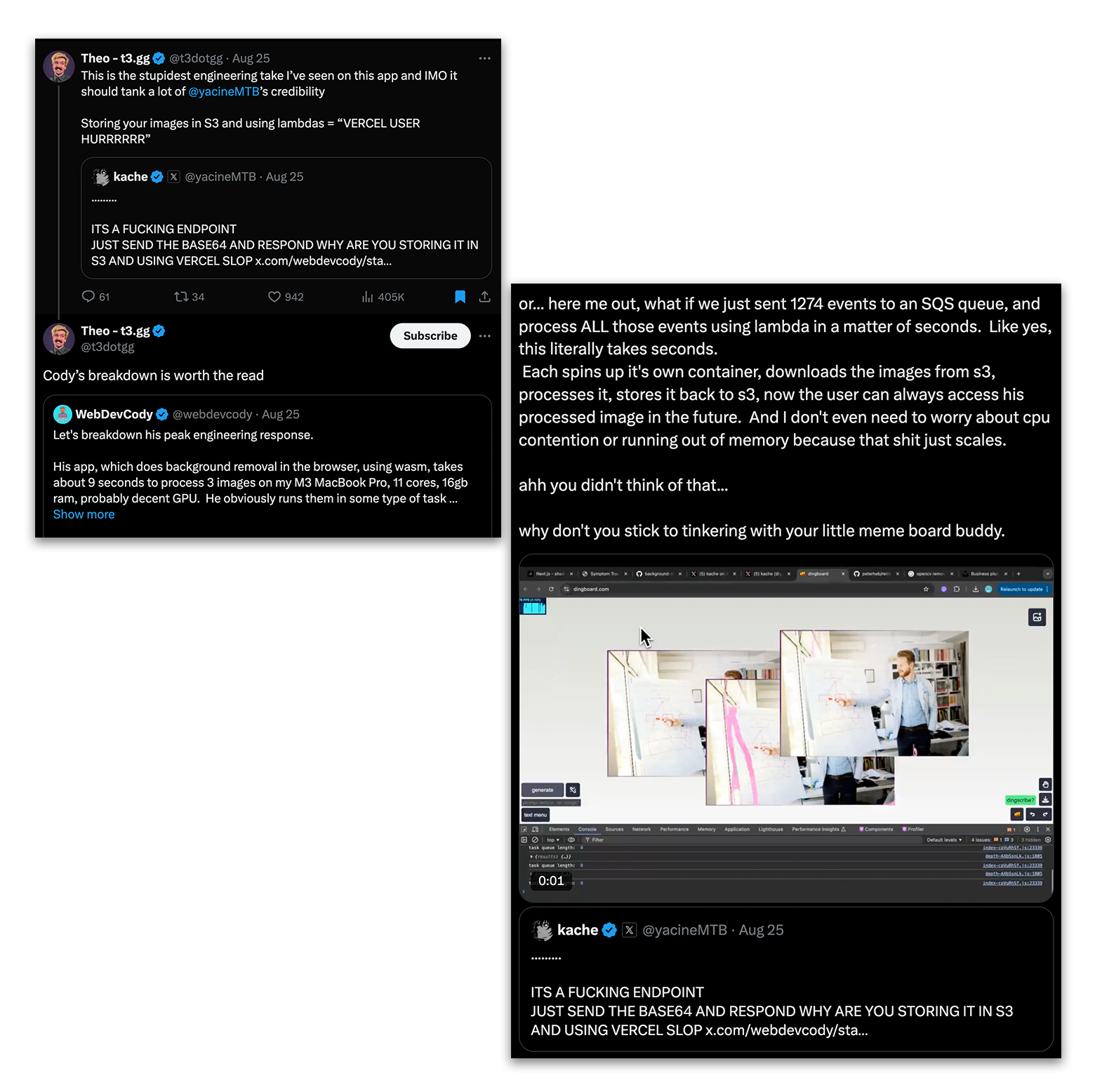
Lafda aside, what caught my eye was Cody’s suggestion to build a scalable publisher-worker infrastructure using SQS and lambda workers. In short, if you want to perform bursty, processing-heavy tasks - a good way is to push these as events into an SQS queue. At the other end of this queue, we have lambda functions being spun up based on the queue length - the larger the queue, the higher the number of lambda workers being spun up to speed up processing. (reference)
While this is probably the best choice for such workloads, I was curious about how one can build something similar without depending on managed offerings from a cloud provider. I’m in no way suggesting that rolling your own alternative to such a system is a good idea, it’s not. This is rather an exercise to satiate that inner engineering itch.
What we’re building
Let’s understand the requirements for the system we’re trying to emulate.
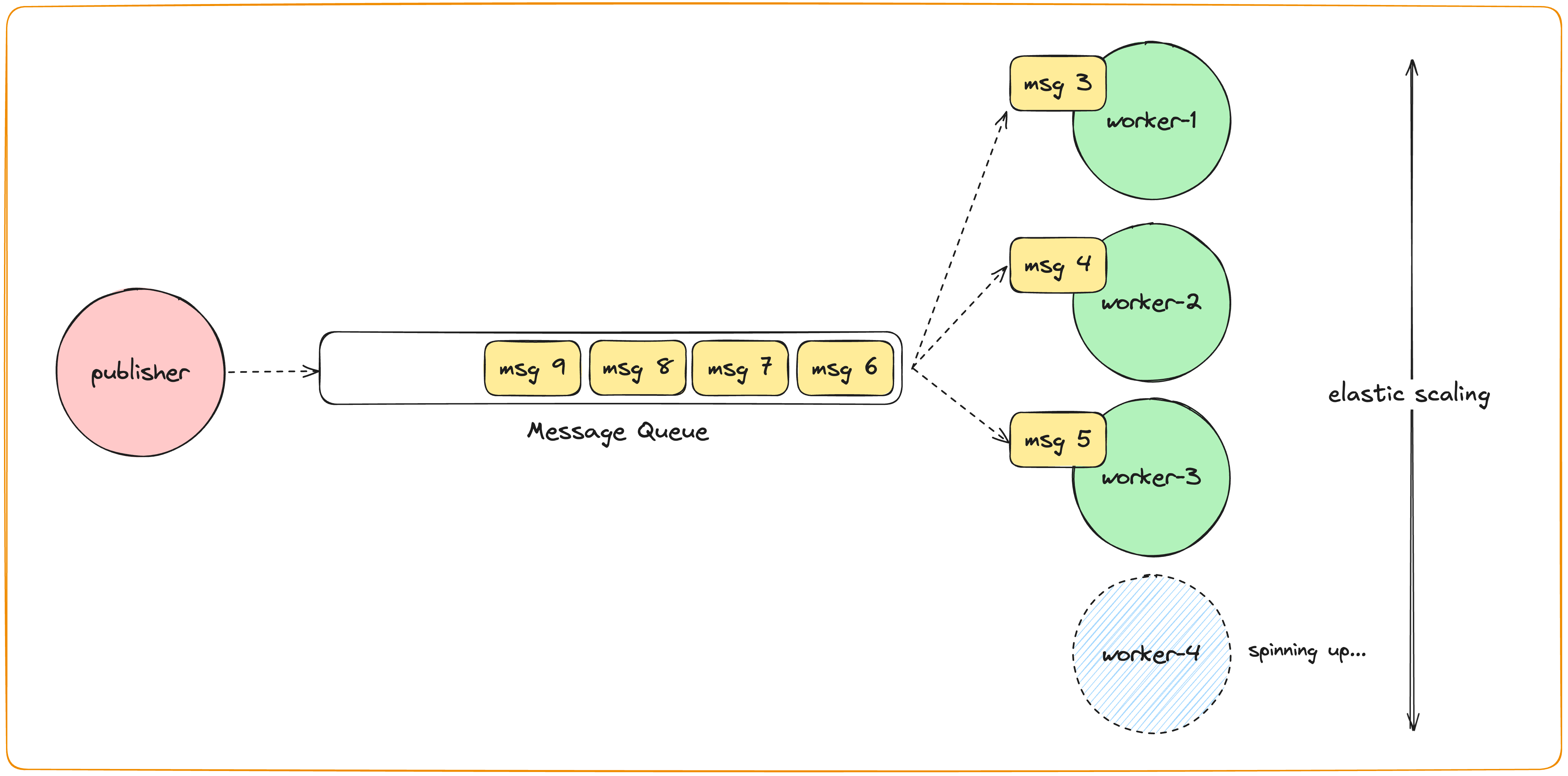
A publisher (or multiple publishers) that generates events.
A FIFO queue to which publishers can send events (or tasks).
Consumers that consume events from the queue.
The number of consumers should autoscale based on the load. For this system, the load parameter will be the length of the queue.
The complete code for this project will be available in the GitHub repository.
RabbitMQ
RabbitMQ is an open-source message broker which implements the Advanced Message Queuing Protocol (AMQP). It acts as a middleman for various services, allowing them to communicate asynchronously by sending and receiving messages.
Since RabbitMQ is a message queue, it delivers each message to only one consumer by default - which is desirable for this use case.
Kubernetes Autoscaling with KEDA
In Kubernetes, the Horizontal Pod Autoscaler (HPA) automatically adjusts the number of pods in a deployment, replication controller, or stateful set based on observed metrics. By default, Kubernetes HPA uses CPU or memory utilization as the scaling metric, but it can also scale based on custom metrics when integrated with other tools.
KEDA allows Kubernetes to scale deployments based on external metrics or event sources (like RabbitMQ queue length, Kafka topic lag, HTTP request rate, or custom metrics). These event sources often represent workload metrics that go beyond traditional CPU and memory metrics.
Autoscaling flow with KEDA
External Event Source Monitoring
KEDA monitors external event sources by creating a ScaledObject custom resource (CRD) in Kubernetes. This ScaledObject links a specific Kubernetes deployment to an external metric (e.g., the number of messages in a RabbitMQ queue or the lag in a Kafka topic). KEDA includes scalers for different event sources, each scaler being responsible for gathering metrics from the external system.
KEDA Creates or Updates the HPA
When KEDA is set up, it automatically creates or updates an HPA object for the associated Kubernetes deployment. This HPA is configured to scale based on the external event metrics provided by KEDA's scalers.
KEDA translates the external event metrics (like the number of unprocessed messages in RabbitMQ) into something Kubernetes can act on.
For example, if the queue length of RabbitMQ exceeds a certain threshold, KEDA informs the HPA about this.
Polling and Metrics Evaluation
KEDA constantly polls the external event source and evaluates the current metric (e.g., RabbitMQ queue size). KEDA performs this polling at a defined interval.
If the metric (e.g., RabbitMQ queue length) exceeds a threshold (for example, more than 50 unprocessed messages in the queue), KEDA signals that more pods are needed to handle the workload.
KEDA then updates the HPA with this information.
HPA Adjusts Pod Replicas
Based on the metrics KEDA provides, the HPA decides whether to scale up or down the number of pods in the associated deployment. The HPA increases the replica count if the metric exceeds the threshold or scales down if it falls below.
For instance, if the RabbitMQ queue length goes above 50, the HPA will increase the number of replicas in the deployment to process more messages.
If the queue length drops below the threshold, the HPA will reduce the number of replicas to save resources.
Dynamic Scaling
This entire process is dynamic and continuous. KEDA keeps checking the external event source, and the HPA adjusts the number of pods accordingly in real time based on the changing external metric.
Pod Scaling Behavior
The actual pod scaling behavior (how fast it scales up or down) is governed by the HPA, which is now enhanced with event-driven metrics from KEDA. Kubernetes schedules the new pods or terminates excess pods as needed.
Putting it all together
Services & Deployments
In our setup, we have three key deployments:
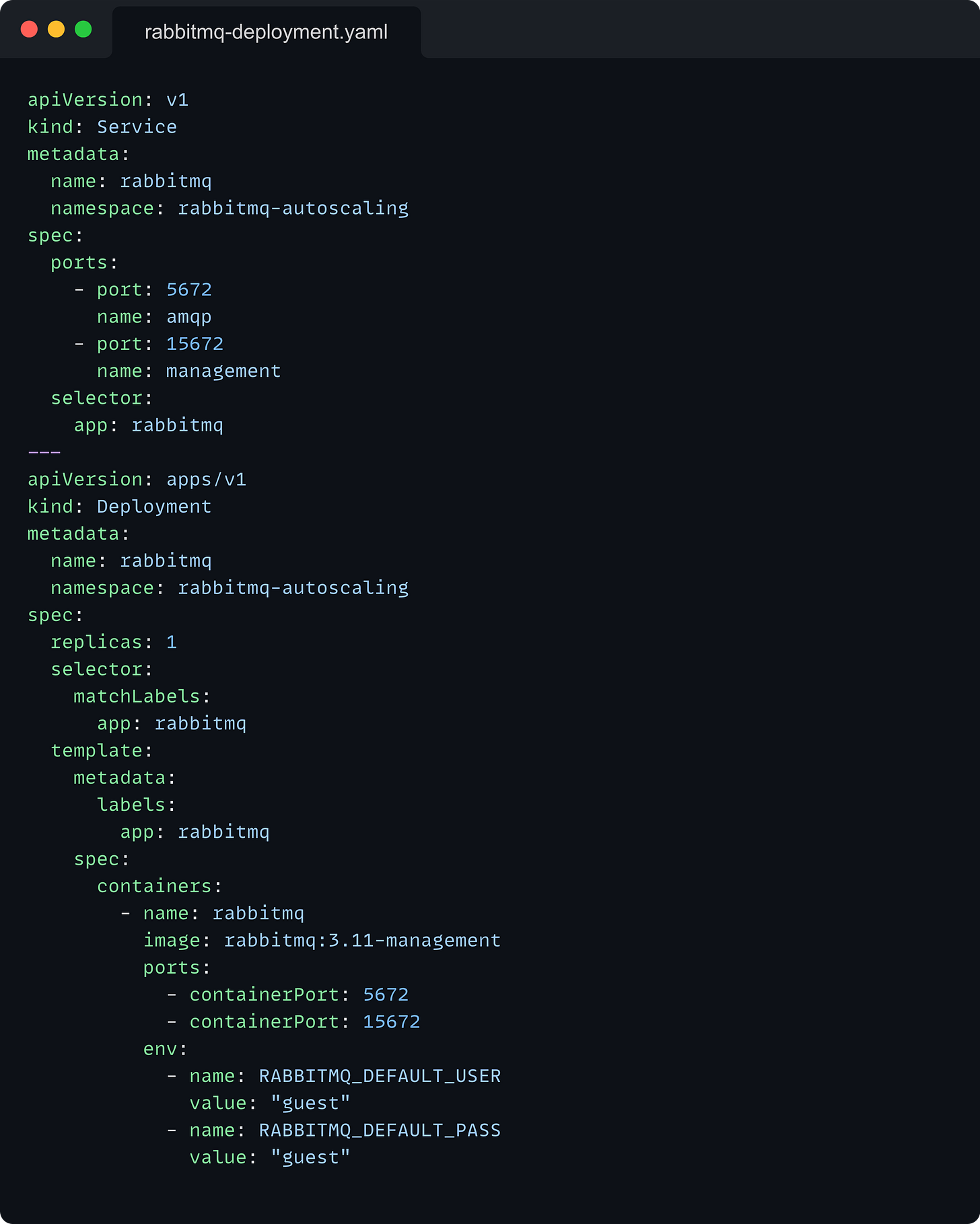
RabbitMQ Deployment: Manages the RabbitMQ server pod.
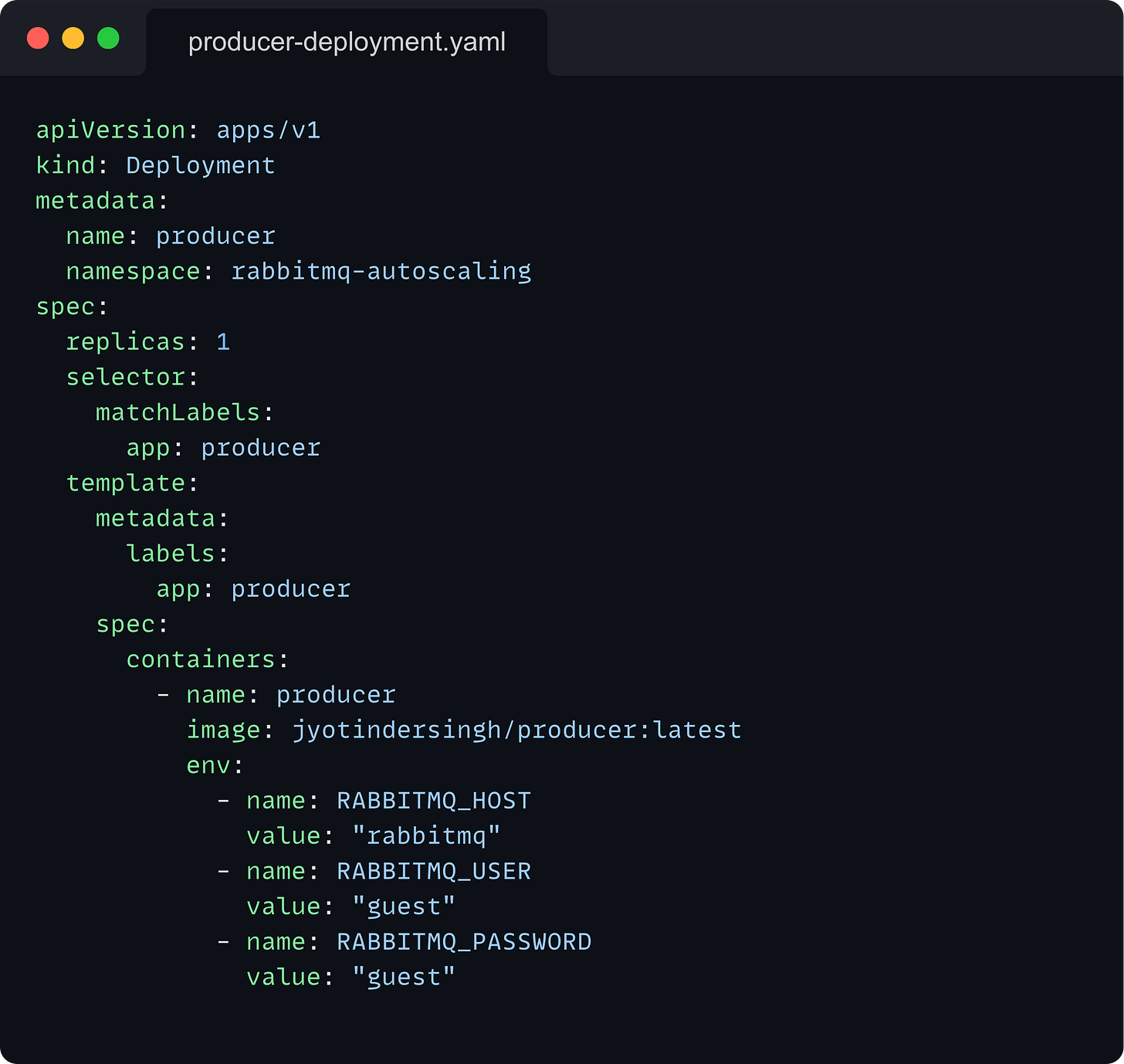
Producer Deployment: Manages the pods that generate and send messages to RabbitMQ.
Consumer Deployment: Manages the pods that process messages from RabbitMQ.
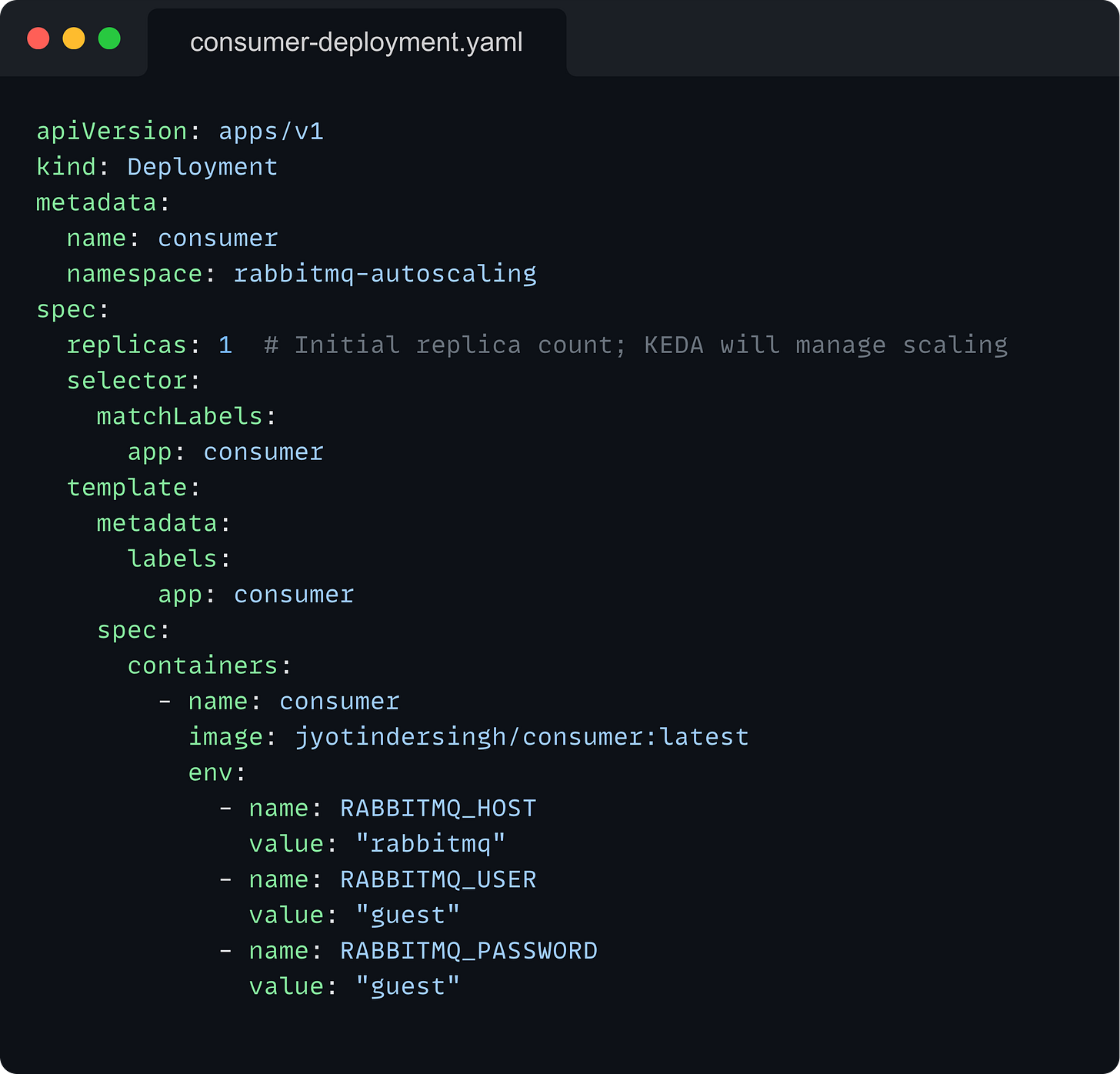
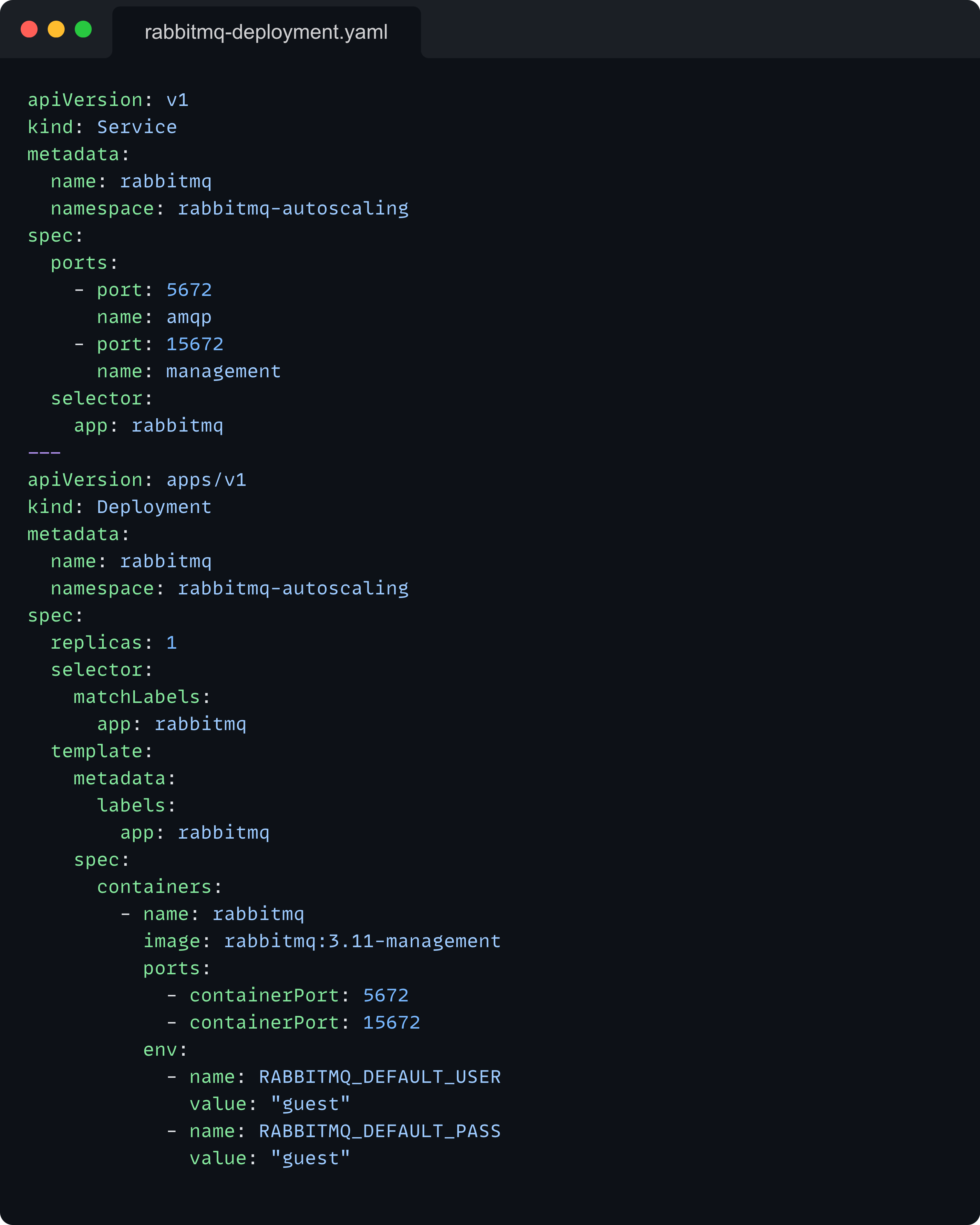
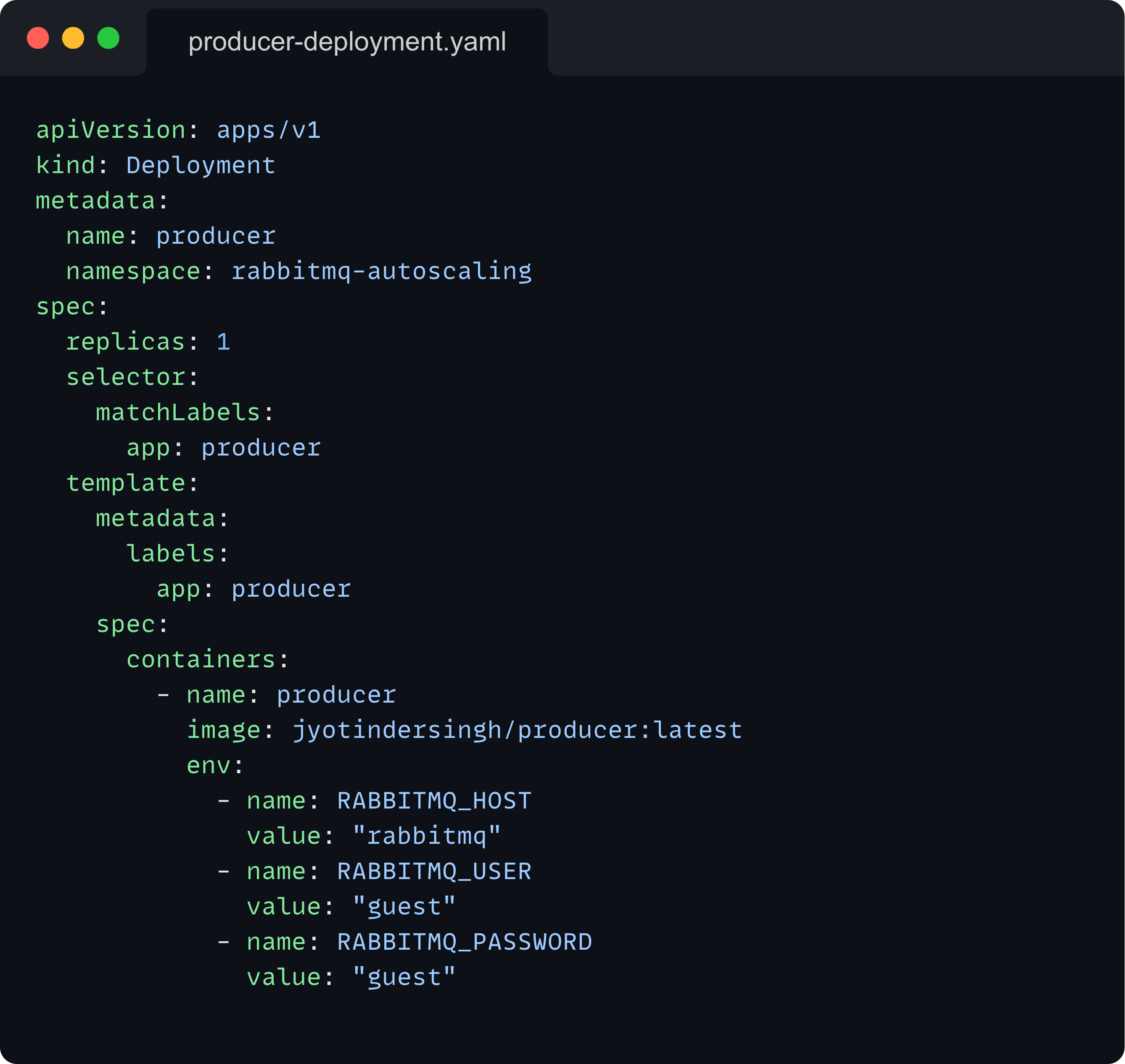
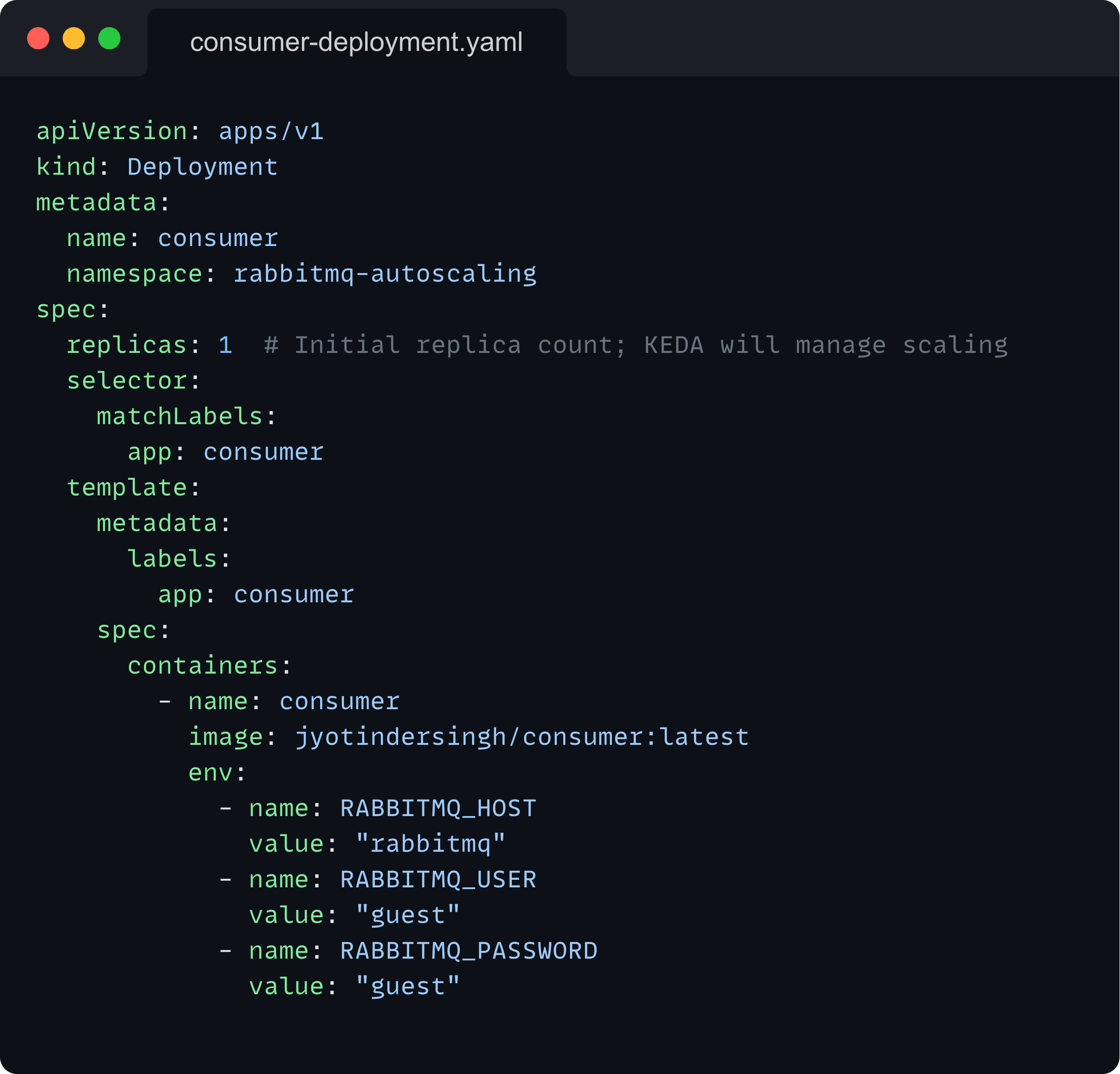
You can view the exact code for the consumer and the producer applications in the GitHub repository. I won’t be covering that here. All you need to know is that the producer generates messages at a much higher rate than what the consumer can handle. This allows us to demonstrate the autoscaling behavior easily.
Secrets
Secrets are used to store sensitive information. We use a Secret to securely store the RabbitMQ connection string, which includes the username and password.
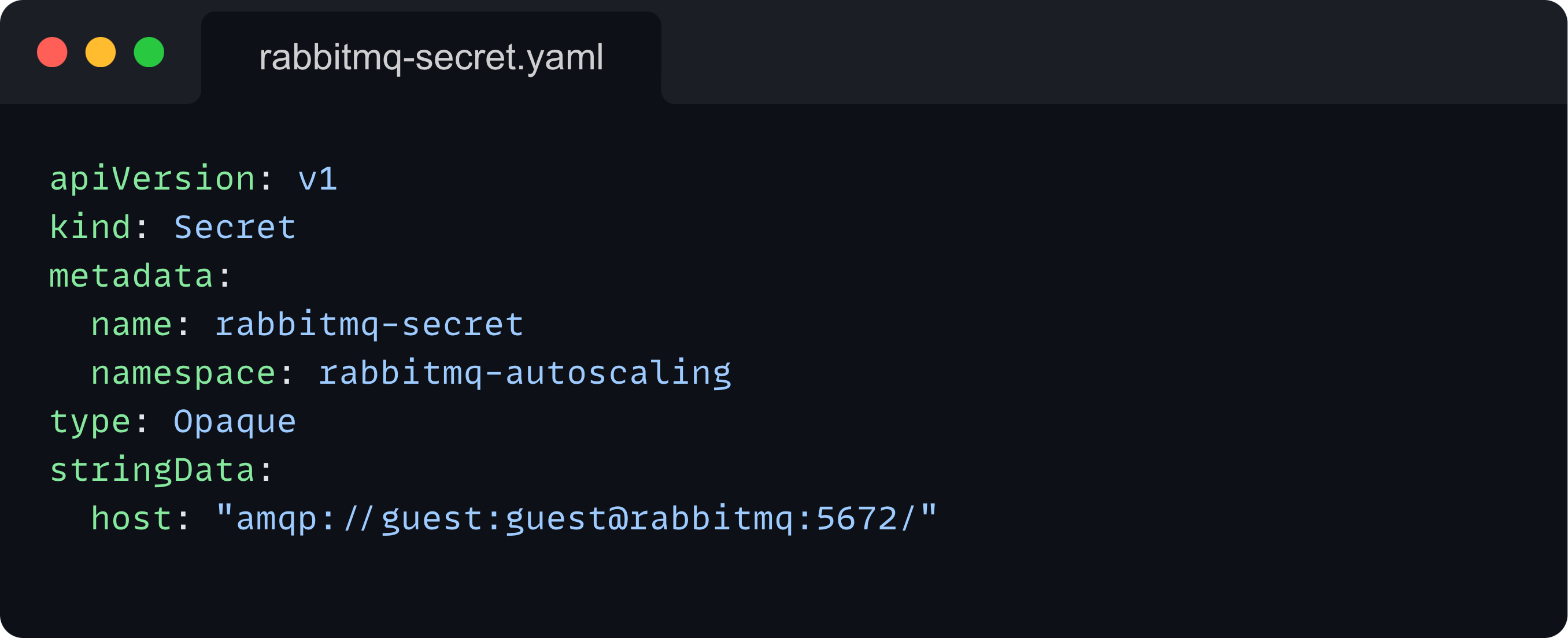
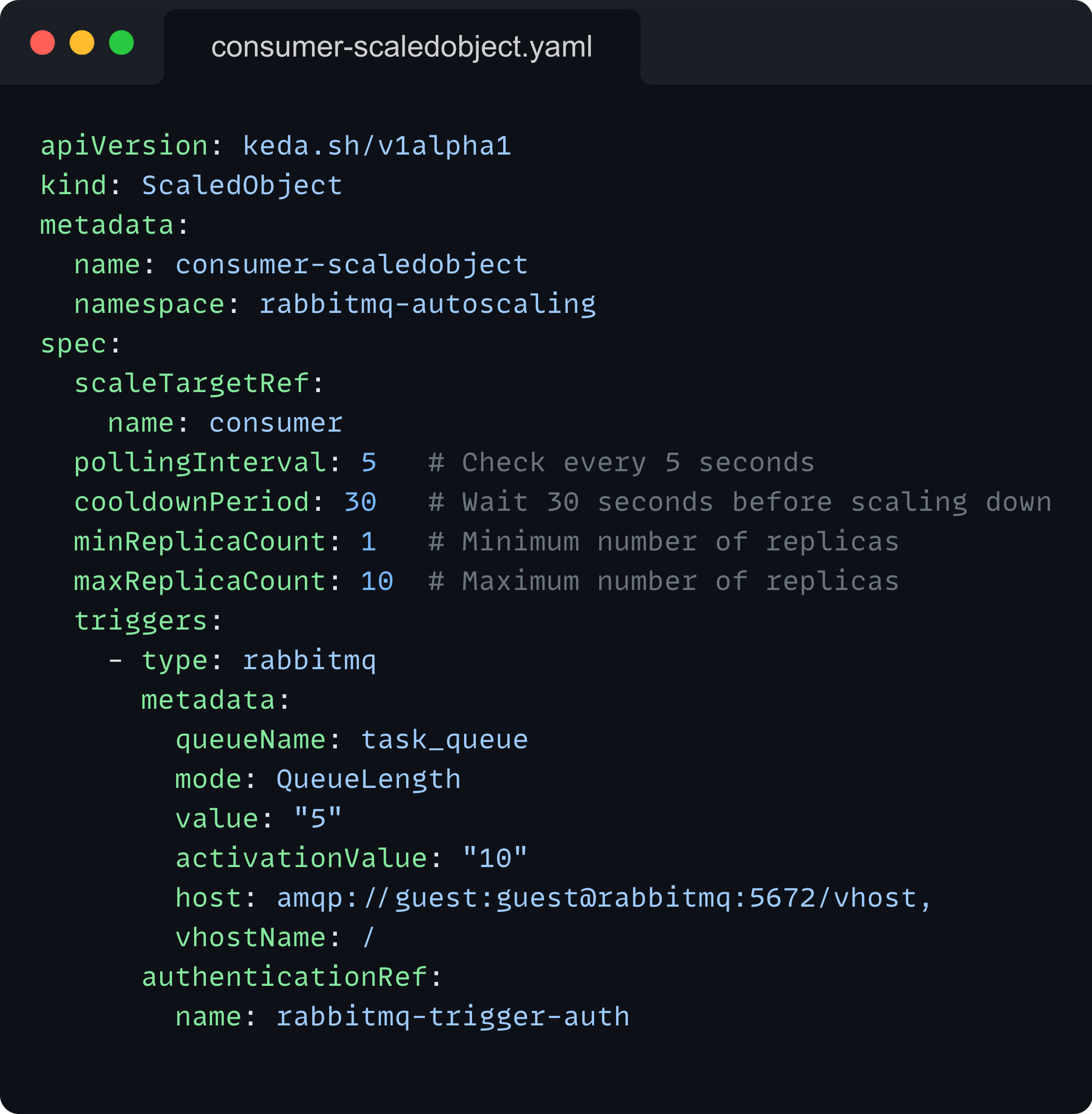
ScaledObject
A ScaledObject is a custom resource defined by KEDA. It specifies how a deployment should be scaled based on external metrics or events. In our setup, the ScaledObject defines:
The target deployment to scale (our consumer)
The scaling parameters (min and max replicas, polling interval, cooldown period)
The trigger for scaling (RabbitMQ queue length)
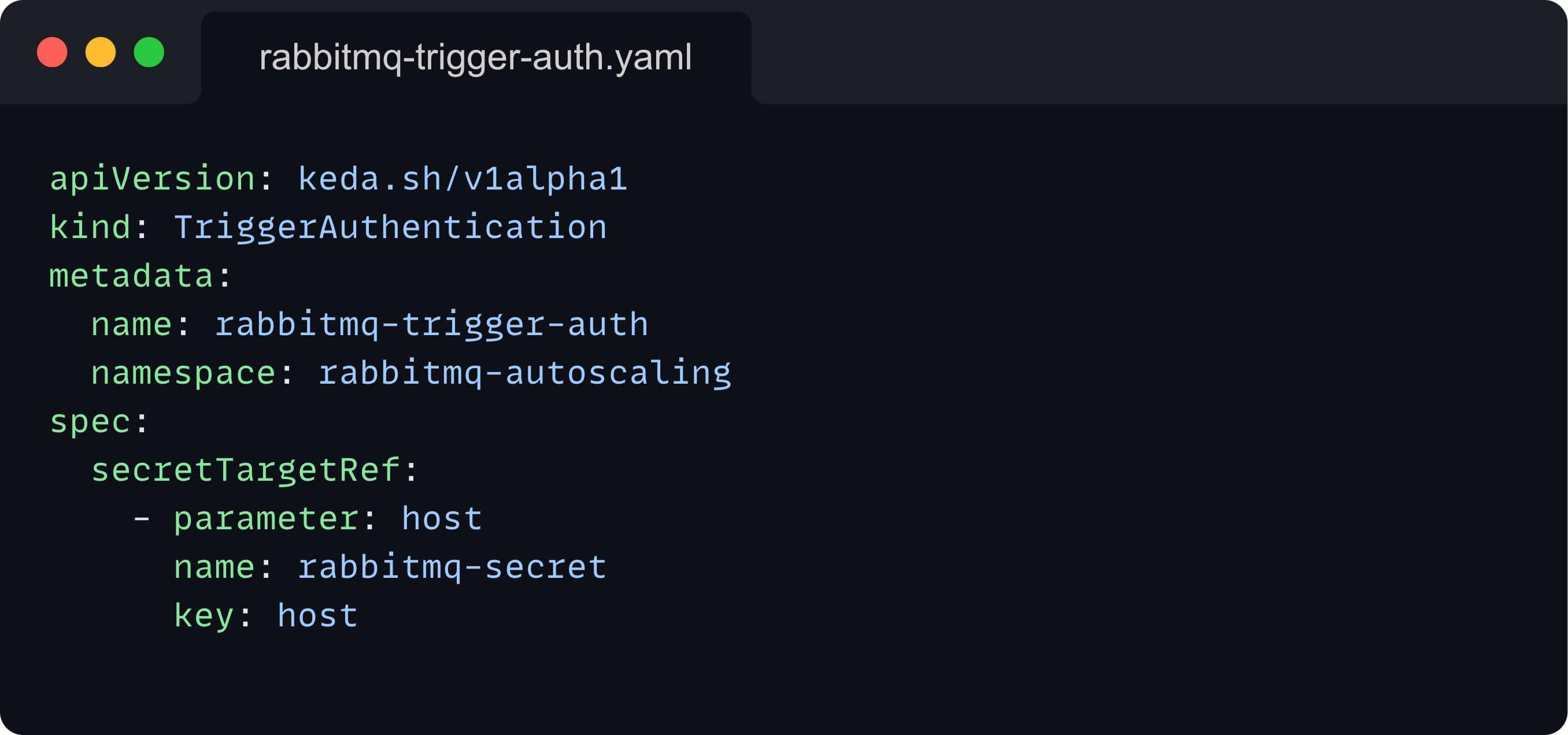
TriggerAuthentication
Another KEDA-specific resource, TriggerAuthentication defines how KEDA should authenticate with RabbitMQ to retrieve queue metrics. It references the Secret containing the RabbitMQ connection information.
These resources work together to create our autoscaling system:
The RabbitMQ Deployment and Service set up the message broker.
The Producer Deployment sends messages to RabbitMQ.
The Consumer Deployment processes messages from RabbitMQ.
The ScaledObject and TriggerAuthentication enable KEDA to automatically scale the Consumer Deployment based on the RabbitMQ queue length.
Trying it out
Instead of listing all the steps to run this setup and seeing the autoscaling in action as a part of this newsletter, I’d rather have you go through the README on the GitHub repository, which will always contain the most up-to-date steps for the same.
If you found this issue useful, be sure to leave a star on the repository. It helps me out a lot!