

Building a Distributed Task Scheduler in Go
System Design & Implementation


Introduction
In this issue, we’ll discuss how we can design a distributed task scheduler, the motivation behind designing such a system, and then implement the same using Go.
You can find the complete code that we’ll be working towards on my github.
The system we talk about here is inspired by Reliable Cron Across the Planet, which is a research article by folks at Google, as well as the insights I picked up in Arpit Bhayani’s System Design Masterclass (which I highly recommend.)
Task Scheduling
Task scheduling is a common and widely needed use case, and every unix machine has a system utility to aid with it. This utility is called Cron and it’s used to run user and system-defined tasks at scheduled times (and intervals).
crond is a singular component that enables cron to do its job - this is a daemon that loads the list of scheduled cron jobs, sorted based on their next execution time. The daemon waits until the first item is scheduled to be executed - which is when it launches the given job, calculates the next time to launch them, and waits until the next scheduled time.
Why are we complicating cron?
Reliability
It’s easy to see the reliability issues with cron - its operation is confined to a single machine responsible for running the scheduler. Consequently, if the machine is offline, the scheduler is inactive, leading to a halt in the execution of scheduled tasks.
Failure Modes
Diving deeper into the failure modes, let us see the kinds of tasks for which one might want to use a scheduler. Some of these tasks can be idempotent, which means in the event of a malfunction it is safe to execute them multiple times.
For example, repeatedly running a job to retrieve the current weather poses no significant issue. On the other hand, certain tasks, like dispatching bulk notifications or processing employee payroll, are sensitive to duplication and should ideally be executed only once.
Similarly, it’s probably okay to skip launching certain jobs in the event of failures - such as updating a weather widget on your laptop every 15 minutes, however, it’s not acceptable to skip the job to process employee payroll that is scheduled to run once every month.
We're immediately confronted with the first trade-off we need to make: should we risk skipping a job or risk executing the same job multiple times? For a lot of use cases, it may make more sense to favor skipping launches over risking duplicate executions. The reasoning behind this choice is straightforward. Setting up monitoring systems to detect skipped or failed launches is typically simpler and more effective than rectifying the consequences of a job that runs multiple times. For instance, reversing the effects of disbursing employee salaries twice or sending a newsletter email multiple times can be complex, if not impossible, in some cases.
For the sake of simplicity, we’ll try to strike a balance between the two options. We will launch any tasks that may have been scheduled to run at a given time or in the past, while also attempting to ensure that the same tasks are not dispatched multiple times during an execution run. Such systems can have extremely sophisticated edge cases and we won’t attempt to handle every single one.
Distributed Cron
To tackle the reliability issues with running cron on a single machine, let’s discuss how we may want to make the application distributed.
A core component of cron is the cron table - which manages the state of the system. The scheduler references this table to decide which task needs to be executed at a given moment. This state is one of the critical aspects of the system that needs to persist across system restarts and failovers. You can go one of two ways to store this state:
Store the state externally in externally distributed storage (eg. HDFS)
Distributed, and therefore reliable.
Optimized for large files (while cron needs to store very small files, which are expensive to write and have high latency).
Introduces an external dependency to a system that may need to be highly available. In case the cron service is a core part of the infra, one should prioritize minimal external dependencies.
Store the state within the cron nodes itself
Need to manage state consensus.
The core system state is not stored in an external dependency.
Storage can be highly optimized for the use case.
More complicated to implement.
While option 2 may make more sense at Google’s scale and SLAs, option 1 is simpler to implement. We’ll be following an approach similar to option 1, by using Postgres to manage the state for our scheduler.
Designing a Distributed Task Scheduler
We'll start from the user's initial interaction and build out the components incrementally. Here's how the system can be structured:
Scheduling
For this design, let’s assume that a task that a user submits has the following information:
A string representing the command or script the worker node should execute.
The time at which the task is supposed to be executed.
Optionally, the user can set up recurring tasks, but let’s not care about that at this stage - since recurring tasks are nothing but regular tasks scheduled multiple times.
When a user submits a task to the system, we need to store it in whatever storage system our scheduler is using for state management. We’ll be using Postgres, however, the exact database you use does not matter, as long as it provides certain levels of guarantees that we expect from the system (which we will soon discuss).
Database Schema Design
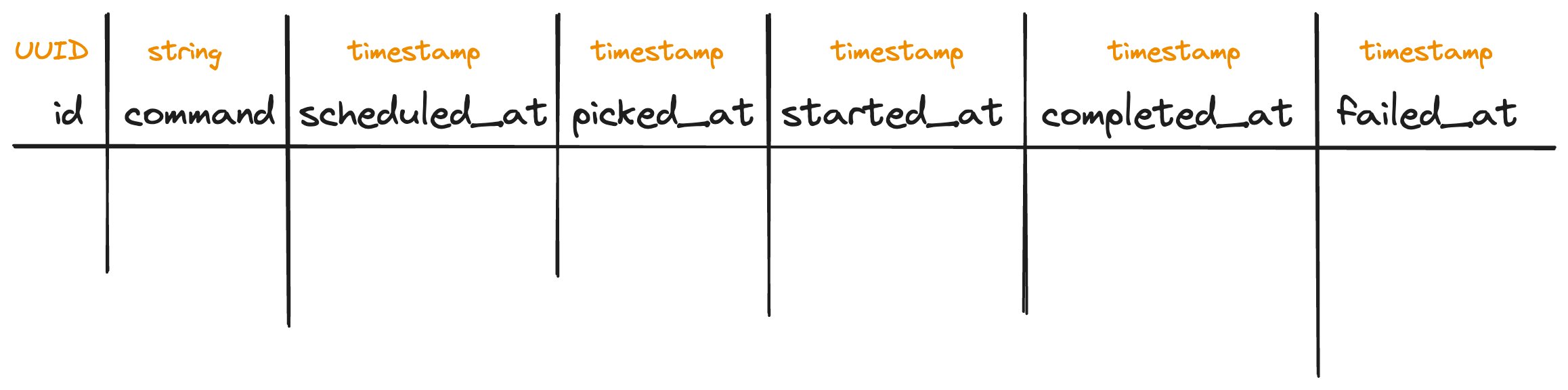
Any task that the user submits should be stored inside our Tasks table. The table stores the following information: uniquely identifies a scheduled task in the system.
Command (string): command that needs to be run to execute the task, this is submitted by the user.scheduled_at (unix timestamp): When the command should be executed.
Further, you may be tempted to store the Status of the task in this table, which would tell us whether the task is queued, in-progress, completed, or failed. However, that introduces a problem. What if the machine that is executing our task (and is supposed to inform us of the task completion) crashes? The status in the table would become inconsistent.
Instead, we’ll adopt a more detailed tracking approach.
Execution Phases Timestamps
For each task, we'll store timestamps for different execution phases (e.g., picked_at (when the task is picked up for execution), started_at (when the worker node started executing the task), completed_at (when the task is completed), failed_at (when the task failed). This approach offers several benefits:
Status Derivation: The current status of each task can be derived from these timestamps. For example, if a task has a 'started_at' but no 'completed_at' timestamp, it's in progress.
System Health and Load Insights: By analyzing the timestamps, we can gauge system performance and load, understanding how long tasks are in the queue, execution times, and if there are any unusual delays.
Recovery and Redundancy: In case of crashes, this detailed historical record allows the system to determine what was happening at the time of failure and take appropriate recovery actions, such as rescheduling tasks or alerting administrators.
With this, we have built the scheduling components of our system.

Task Picking
In a distributed task scheduler, effectively managing task execution is crucial. We face a significant challenge: How to handle potentially thousands of tasks scheduled at the same time without overwhelming the database with requests or causing execution conflicts.
Challenges and Considerations
Independent Worker Fetching Drawback: Initially, one might consider allowing workers to independently fetch tasks from the database. However, this approach is prone to causing excessive concurrent connections and overwhelming the database in a large-scale environment.
Need for a Coordinated Approach: To address the limitations of independent fetching, we introduce a coordinator. This component is responsible for picking tasks currently scheduled for execution and delegating them to workers.
Implementing Coordinator-Led Task Assignment
The coordinator will fire queries on the database every few seconds to pick the tasks currently scheduled for execution. Let’s see what such a database query may look like. The coordinator will start a transaction, and fire the following SELECT query.
SELECT id, command
FROM tasks
WHERE scheduled_at < (NOW() + INTERVAL '30 seconds')
AND picked_at IS NULL
ORDER BY scheduled_at
LIMIT 10;The above SQL query fetches all the tasks that are scheduled to be executed before the next 30 seconds and have not yet been executed.
For this query to work, every time the coordinator picks a task for execution, it must update the picked_at field. We can fire the following UPDATE query as a part of the overall transaction for each task that we pick:
UPDATE tasks SET picked_at = NOW() WHERE id = <task_id>;Remember, the coordinator should be a distributed service, so that it can scale up based on the load on the system. This would mean if multiple coordinators fire this query on the database at the same time, they will end up picking the same tasks - causing multiple executions. To deal with this, each coordinator needs to lock the rows that it is working on.
We can make use of the FOR UPDATE clause to take an exclusive lock on the rows that each coordinator is working on. This means, that the transactions started by the other coordinators won’t be able to select these rows while the current coordinator is operating on them.
SELECT id, command
FROM tasks
WHERE scheduled_at < (NOW() + INTERVAL '30 seconds')
AND picked_at IS NULL
ORDER BY scheduled_at
LIMIT 10
FOR UPDATE;There is still one problem with this query. Say 10 different coordinators fire the select query at the same time, each of them will try to pick up the top 10 tasks that are scheduled for execution. However, only one of them will be able to acquire a lock on these 10 rows. This means the rest of the 9 coordinators will end up blocking in contention over the same 10 rows that the first coordinator is already processing.
The SKIP LOCKED clause is introduced to prevent coordinators from blocking each other over the same tasks. This allows each coordinator to bypass tasks already locked by others, ensuring smooth and efficient task distribution.
SELECT id, command
FROM tasks
WHERE scheduled_at < (NOW() + INTERVAL '30 seconds')
AND picked_at IS NULL
ORDER BY scheduled_at
LIMIT 10
FOR UPDATE SKIP LOCKED;Once a coordinator has selected a bunch of tasks, it can start delegating them to the workers in its worker pool.
Execution
The execution phase is straightforward. Workers remain on standby, awaiting tasks from the coordinator. The workers maintain an internal pool of threads to execute the tasks they receive. Any tasks sent to the workers get added into a thread-safe channel from where the threads can pick up these tasks.
The moment a task is assigned, they begin execution. They promptly notify the coordinator upon starting a task, enabling it to update the task's status in the database accordingly. Likewise, upon task completion or failure, the workers communicate the outcome back to the coordinator for a further update.
Therefore, our system ends up as follows

Implementation
It’s hard to discuss code in a newsletter, so I decided to go over the implementation on my YouTube channel. You can check it out here:
Conclusion
In this article we discussed the design of a distributed task scheduler, offering a way to overcome the limitations of regular cron. We explored key concepts like task scheduling with detailed timestamps, and task picking with efficient locking strategies. Finally, we went over the code to understand how you can build such a system in Go.
we are using a shared database . that is an anti pattern. can you plz clarify
thanks for the article, learnt a lot!
i am implementing a similar system using golang, as a resume project. this article helped a lot!