



Why Meta's mission critical storage system uses a low-efficiency, high-latency replication algorithm
The algorithm from 2004 that powers replication for Meta's mission critical storage layer.


Meta’s build and distribution artifacts storage service is called Delta - a highly available, and strongly consistent storage service. Anything highly available is usually distributed, and anything distributed usually relies on certain algorithms to maintain consensus and consistency among the different nodes.
Distributed systems typically rely on a quorum-based replication method. This approach, which includes well-known strategies like Paxos and Raft, is designed to achieve good performance metrics such as low latency, high throughput, and seamless automated failover.
However, quorum-based replication has two significant challenges:
Eventual consistency: With Paxos and Raft, the system writes data via a leader node, but any follower node can handle reads. The leader sends the write request to all followers and waits for a majority to acknowledge before confirming the write's completion. But since any node can respond to read requests, there's a chance a follower that hasn't yet received the latest updates might serve outdated data to a client. This scenario, known as eventual consistency, can lead to inconsistencies in the data viewed by the client.
Complicated consensus and failover: If the leader node fails, these systems use a leader-election algorithm to choose a new leader from the followers. This is a complex task involving a sophisticated voting process, making the failover mechanism difficult to predict and monitor.
Meta needed a storage solution that guarantees strong consistency, has a simple consensus algorithm, needs minimal external dependencies, and has a fast and straightforward failure detection and recovery process. Therefore, they decided to go ahead with a rather unconventional replication strategy for Delta, called Chain Replication.
This strategy was first discussed in a paper that came out in 2004. Before going deeper into our discussion about Delta, let us understand how this replication strategy works.
Chain Replication
As the name suggests, the nodes in a chain replication-based distributed system are laid out in a linear, chain-like format, similar to a linked list. Each node in this chain redundantly stores replicas of all the objects stored in the system.
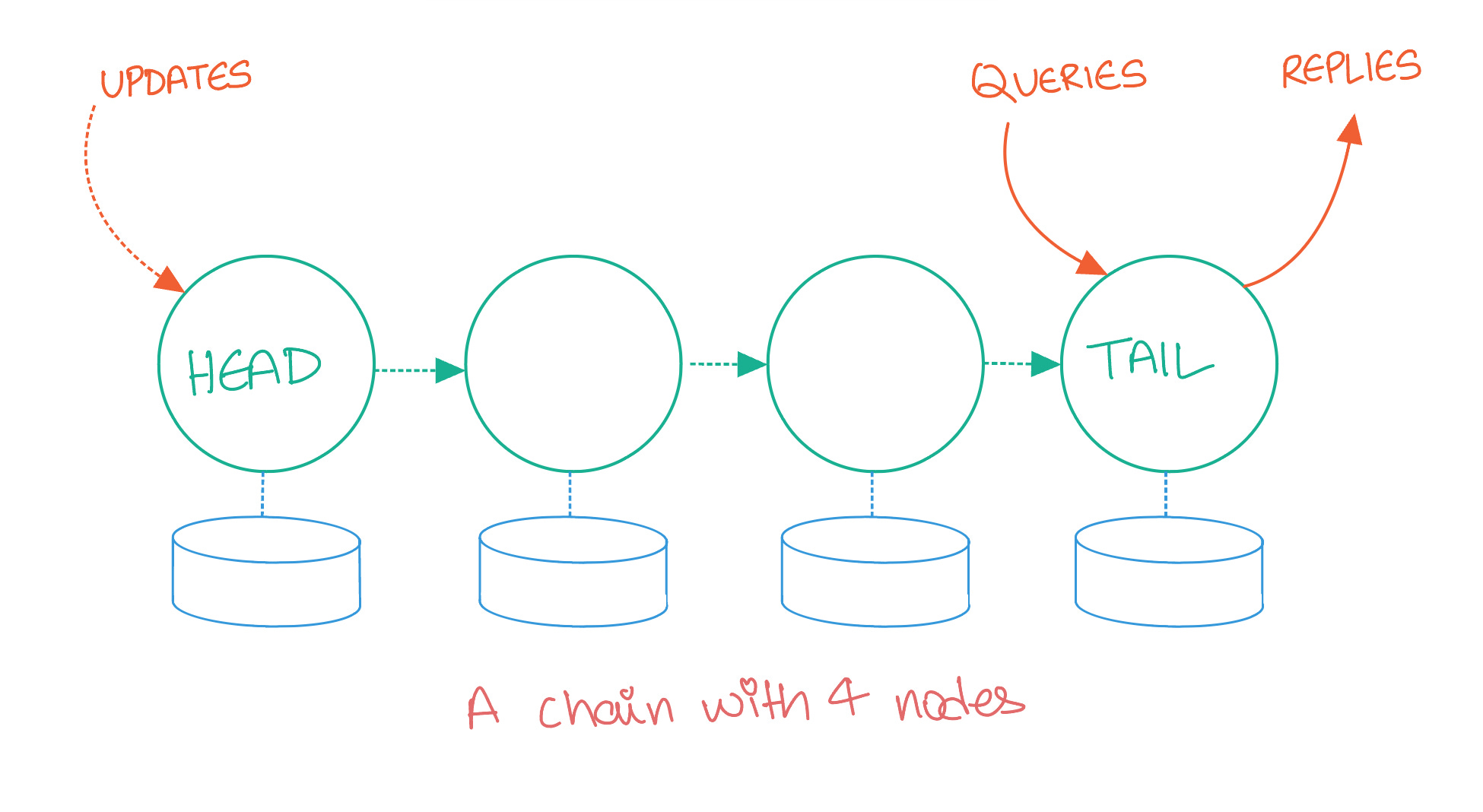
The first server in the chain is called the Head, and the last server is called the Tail. All writes to the system are serviced by the Head. Once the write is persisted to the Head node’s storage, it is propagated to the next server in the chain and this process continues until the update reaches the Tail. The Tail node then acknowledges the write, back to the client.
Read requests are serviced only by the Tail server. If a client reads an object from the Tail it is guaranteed that this object must have been replicated to every other server in the chain, guaranteeing strong consistency.
Performance
Since writes must be propagated through the entire system before being acknowledged, the write latency in a chain-replication-based system is usually higher than quorum-based strategies. The reads are always serviced by a single host server (the Tail), therefore, this can easily become a bottleneck.
Apportioned Queries
While there is not much that can be done about write latency, we can definitely optimize the read latency.
Object Storage on CRAQ, a paper from Princeton defines a strategy for “Apportioned Queries” (apportion: “divide, share out”).
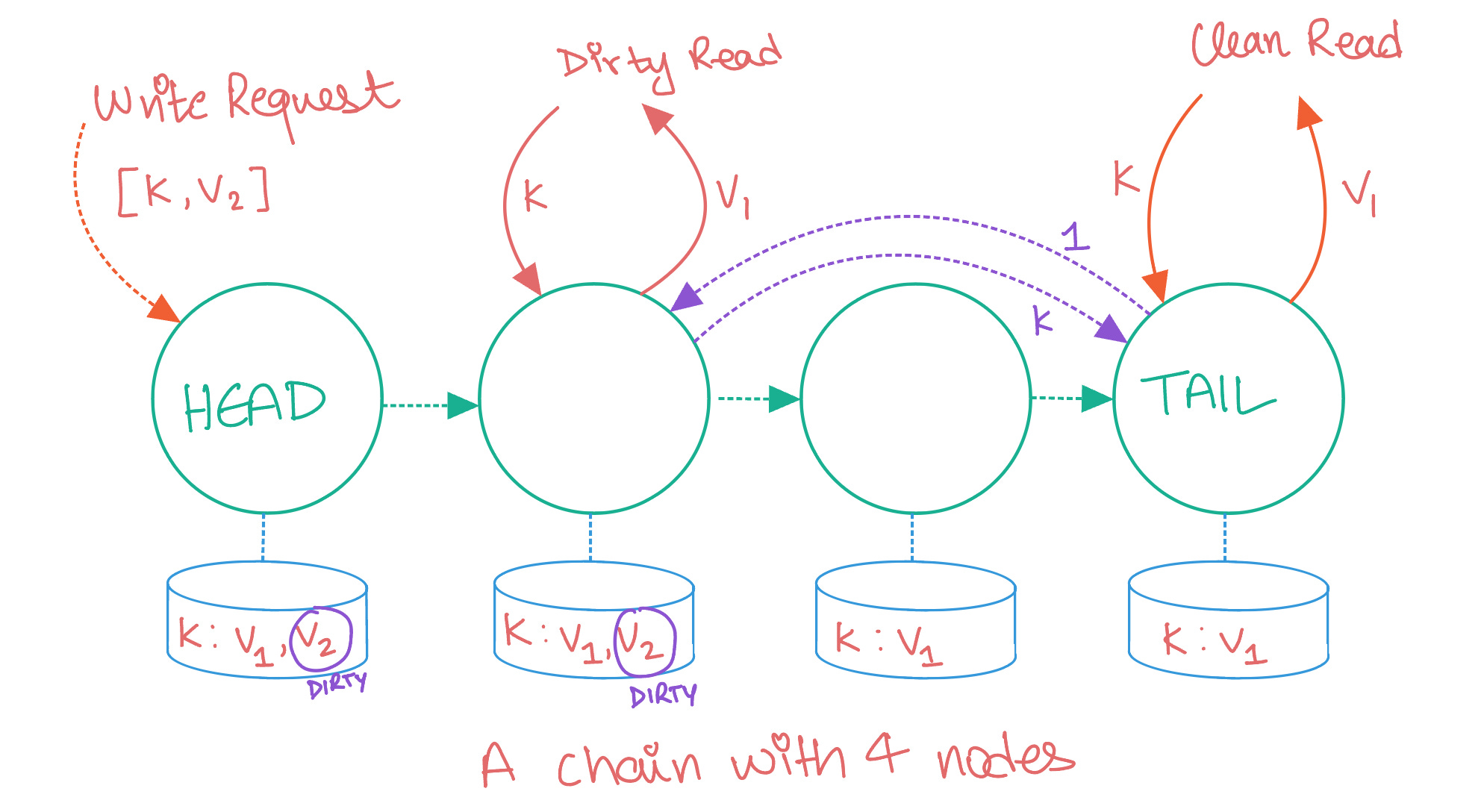
In this strategy:
Each node in the chain can store multiple versions of an object, each including a monotonically increasing version number and an additional attribute whether the version is clean or dirty. All versions are initially marked as clean.
When a node receives a new version of an object (via a write being propagated down the chain), it appends this latest version to its list for the object.
If the node is not the tail, it marks the version as dirty and propagates the write to its successor.
Otherwise, if the node is the tail, it marks the version as clean, at which time we call the object version (write) as committed. The tail node can then notify all other nodes of the commit by sending an acknowledgment backward through the chain.
When an acknowledgment message for an object version arrives at a node, the node marks the object version as clean. The node can then delete all prior versions of the object.
When a node receives a read request for an object:
If the latest known version of the requested object is clean, the node returns this value.
Otherwise, if the latest version number of the object requested is dirty, the node contacts the tail and asks for the tail’s last committed version number (a version query). The node then returns that version of the object; by construction, the node is guaranteed to be storing this version of the object.
Even though the tail could commit a new version between when it replied to the version request and when the intermediate node sends a reply to the client, this does not violate our definition of strong consistency, as read operations are serialized with respect to the tail.
The benefits of this strategy depend on the read patterns. Older keys can be served independently by any link in the chain, however, requests to read recently updated keys (which might be marked as dirty) will still need to consult the tail node.
Meta implemented apportioned queries in Delta (which largely uses 4-link chains), and saw an almost 50% increase in read throughput.
Delta
Delta’s architecture consists of the concept of Buckets, where each bucket could potentially belong to one customer. Each delta bucket can include several chains, each of which contains four or more servers.
Each chain in a bucket can be considered as a logical shard of the data which serves a part of the data and traffic. Servers in a particular chain are spread across failure domains such as power and network.
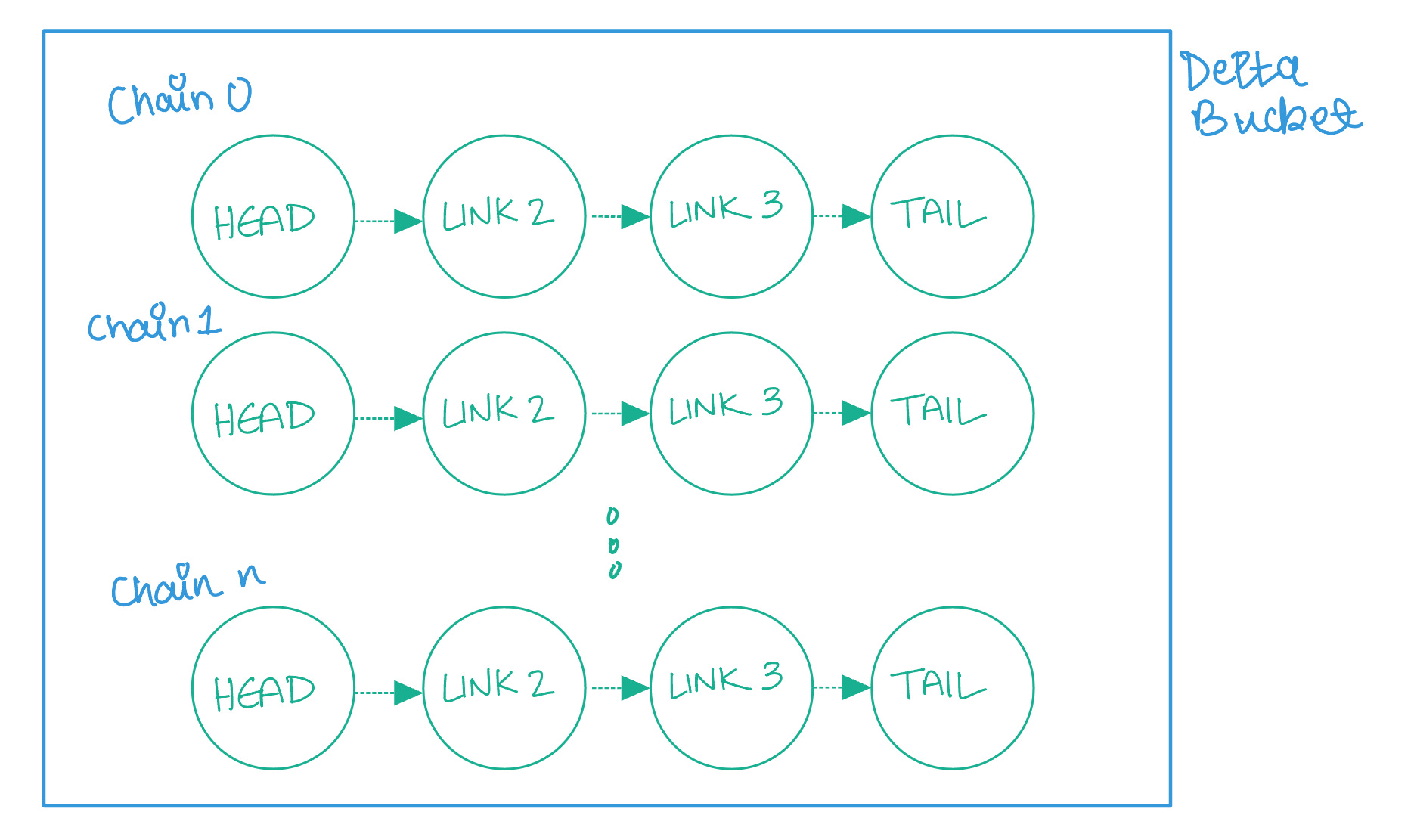
When clients access an object within a Delta bucket, a consistent hash of the object name selects the appropriate chain to query.
Delta stores the bucket configuration metadata in a metadata service, which is built on top of Zookeeper. Clients depend on this bucket configuration to determine which hosts to make requests to - Head for writes, Tail (or other nodes in case of Apportioned Queries) for reads. Since Delta is focused on serving critical package workloads, and other low-dependency use cases. Delta’s only dependency is this bucket config store.
Failure Detection & Recovery
The original chain replication paper puts the duties of failure detection and recovery on an external service, whereas, in Delta, the nodes in the chain detect failures for the peers themselves.
If a host becomes unavailable, Delta assumes servers to be fail-stop. This means the server halts in response to a failure, rather than accidentally transitioning to an erroneous state. This halt can usually be detected by other hosts sharing a chain with it. This can be implemented using a simple heartbeat mechanism coupled with a timeout.
We would usually not trust the observation of a single sibling server to decide whether another host is down or not - rather, we would want multiple servers to mark a suspicious server as misbehaving before taking action. In Meta’s case, they wait until at least 2 links mark a particular host as suspicious before taking action.
Once a host recovers, it can be added to the back of the chain, where it can wait to synchronize and catch up with the rest of the system. During this time, the host cannot serve reads, and must defer them to the upstream link. However, it can still accept writes it receives from the upstream host.
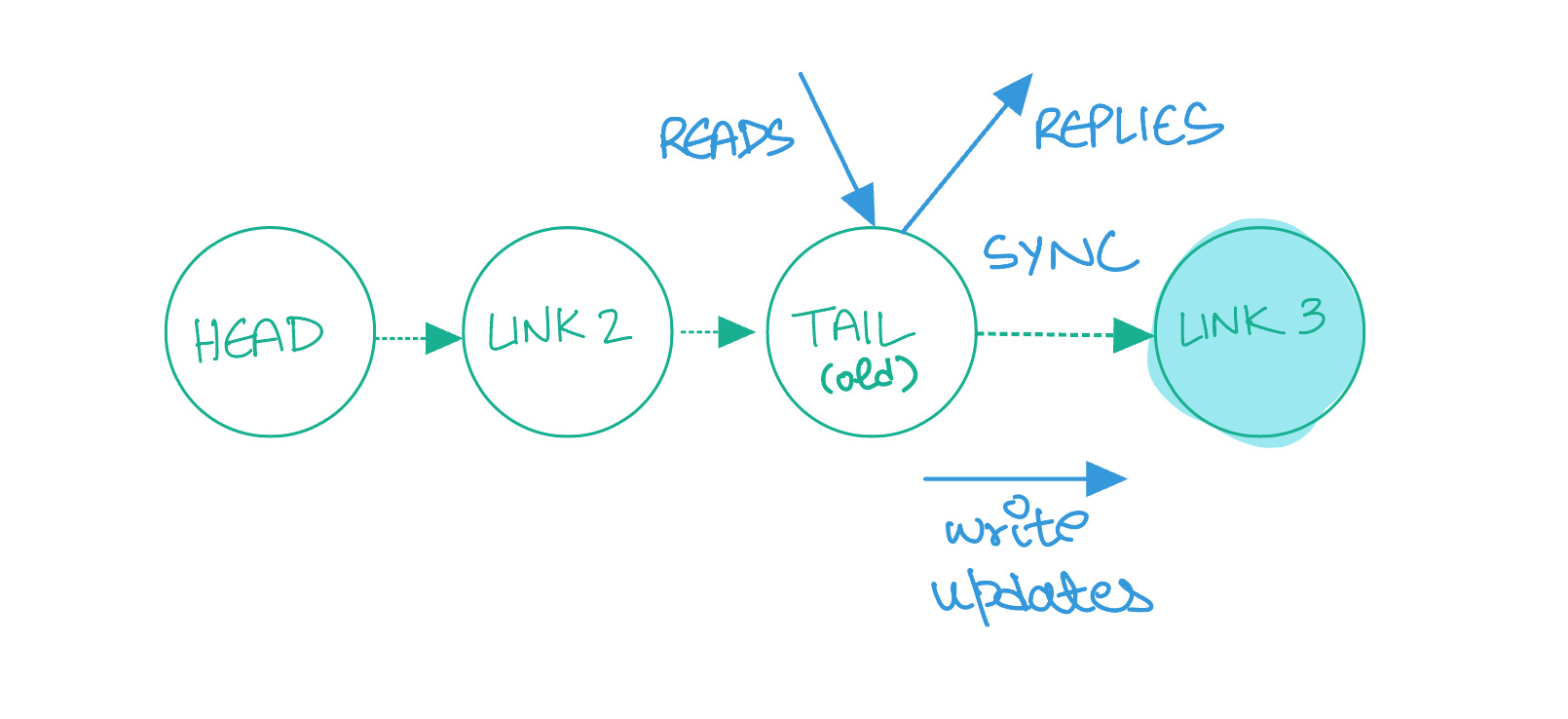
Automated Repair
Delta also maintains a separate fleet management Control Plane Service called Ringmaster, an automated control plane focused on repairing Delta buckets.
Each ringmaster instance monitors a single delta bucket. Whenever any chain in the bucket is missing a link, the ringmaster attempts to repair it and attach the repaired host to the tail. It is always preferable to fix the chain using the original host by repairing it instead of commissioning a new one - since the original machine would have most of the blobs of the chain present in its media (and we would not have to wait for the entire data to be synced to a fresh machine).
The Ringmaster also maintains the failure domain distribution of each chain, to ensure bucket hosts are spread evenly across all domains.
Conclusion
Chain replication allows Delta to provide a strongly consistent, and highly available object store to its upstream services. The algorithmic simplicity of the service allows it to be “low-dependency”, which means it’s fairly isolated from external outages in dependent services which could, in turn, take it down. The simplicity of the replication and failover logic also means that it is easier to customize the recovery processes and decisions based on the system’s need - failover can prioritize the repair of failed nodes over commissioning new ones to make recovery efficient. The simplified topology also allows the service to evenly spread the logical shards across failure domains.
References
https://engineering.fb.com/2022/05/04/data-infrastructure/delta/
https://www.cs.cornell.edu/home/rvr/papers/OSDI04.pdf
https://www.usenix.org/legacy/event/usenix09/tech/full_papers/terrace/terrace.pdf