

Building a Write-Optimized Database Engine: Compaction and Crash Recovery (Part 5)
Handling read and write amplification in log-structured storage engines, and recovering from unexpected oopsies


In this issue, we explore strategies to optimize on-disk storage utilization within our log-structured storage engine, alongside enhancing data durability in the face of application crashes.
So far, we have designed our storage engine to handle reads efficiently, writes, updates, and deletions. However, the continuous influx of writes to our system presents two critical challenges:
Write Amplification: Our storage model, which leaves previously written entries unmodified on disk, representing deletions as tombstones, and updates as new entries - inevitably leads to excessive consumption of physical disk space compared to the actual logical data stored. This issue is particularly problematic in applications with frequent updates.
Read Amplification: The accumulation of SSTable files on disk increases the latency of read operations. As the number of these files grows over time, the engine must navigate an increasingly vast search space to service read requests. Particularly for range scans, which require scanning all storage structures present in our storage engine.
If you want to catch up on the previous issues, you can find them here.
Compaction
Given the challenge posed by the increasing number of disk-resident SSTables in an LSM Tree, which can cause read and write amplification issues over time, introducing a mechanism for ongoing maintenance is important. Compaction serves as this essential maintenance job within an LSM Tree.
Compaction is a background process responsible for merging multiple Sorted String Tables into a single, consolidated SSTable. This operation is important for enhancing our storage engine's efficiency for several reasons. Firstly, it helps in reclaiming disk space by eliminating keys that have been deleted or overwritten, directly addressing the write amplification issue. Secondly, by consolidating data into fewer files, compaction significantly streamlines read operations. It reduces the number of SSTables a read query must traverse, thereby mitigating read amplification and speeding up data retrieval.
Tiered Compaction
Our LSM Tree implementation will use a Tiered Compaction strategy, where SSTables are organized into levels, and compaction rules are applied based on the number of SSTables in each level. Compaction is initiated when the number of SSTables at any level surpasses a predefined threshold. In such cases, we merge all SSTables present at that level into a singular new SSTable, which is then progressed to the next higher level.
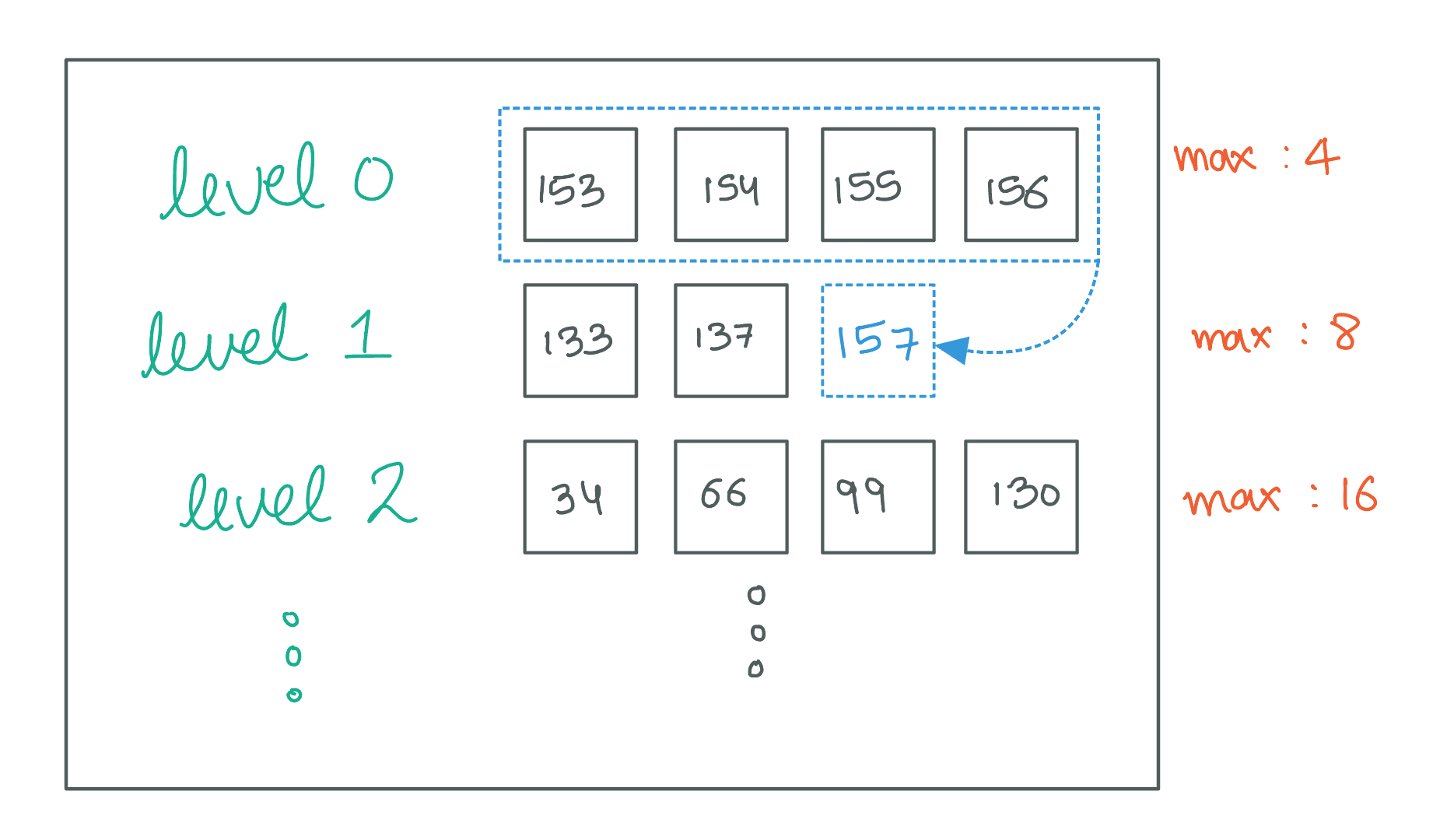
Let's break down the steps to implement this.
Maximum SSTables per Level
We start by limiting the maximum number of SSTables allowed in each level. This limit increases exponentially as we move up the levels. Here's the configuration I’ll be going with:
![// Maximum number of SSTables in each level before compaction is triggered. var maxLevelSSTables = map[int]int{ 0: 4, 1: 8, 2: 16, 3: 32, 4: 64, 5: 128, 6: 256, }](https://substackcdn.com/image/fetch/$s_!Qm1f!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fba83bd5d-4ece-427a-a266-7dc6f1be7d87_2856x1188.png "// Maximum number of SSTables in each level before compaction is triggered. var maxLevelSSTables = map[int]int{ 0: 4, 1: 8, 2: 16, 3: 32, 4: 64, 5: 128, 6: 256, }")
Background Compaction Process
We implement a background process that listens for compaction triggers. We will launch this as a separate goroutine as a part of the Open() method alongside the backgroundMemtableFlushing goroutine that we discussed in the previous issue.
 (*LSMTree, error) { ... lsm.wg.Add(2) go lsm.backgroundCompaction() go lsm.backgroundMemtableFlushing() ... }")
This goroutine will actively monitor the compactionChan channel and wait for any level’s index to be added to it. Whenever it finds a new level added to the channel, it checks where it exceeds its SSTable limit. If it does, it triggers a compaction.
The goroutine gracefully exits upon receiving a cancellation signal, ensuring that all pending compactions are completed.
![// Continuously listen on compactionChan for levels that need to be compacted. // Runs a tiered compaction on the LSMTree. When the context is cancelled, // return. func (l *LSMTree) backgroundCompaction() error { defer l.wg.Done() for { select { case <-l.ctx.Done(): // Finish pending compactions. if readyToExit := l.checkAndTriggerCompaction(); readyToExit { return nil } case compactionCandidate := <-l.compactionChan: l.compactLevel(compactionCandidate) } } } // Check if all levels have less than the maximum number of SSTables. // If any level has more than the maximum number of SSTables, trigger compaction. // Returns true if all levels are ready to exit, false otherwise. func (l *LSMTree) checkAndTriggerCompaction() bool { readyToExit := true for idx, level := range l.levels { level.mu.RLock() if len(level.sstables) > maxLevelSSTables[idx] { l.compactionChan <- idx readyToExit = false } level.mu.RUnlock() } return readyToExit }](https://substackcdn.com/image/fetch/$s_!im9o!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fb7c70548-97d9-4ebe-8289-24f967646abf_3071x3204.png "// Continuously listen on compactionChan for levels that need to be compacted. // Runs a tiered compaction on the LSMTree. When the context is cancelled, // return. func (l *LSMTree) backgroundCompaction() error { defer l.wg.Done() for { select { case <-l.ctx.Done(): // Finish pending compactions. if readyToExit := l.checkAndTriggerCompaction(); readyToExit { return nil } case compactionCandidate := <-l.compactionChan: l.compactLevel(compactionCandidate) } } } // Check if all levels have less than the maximum number of SSTables. // If any level has more than the maximum number of SSTables, trigger compaction. // Returns true if all levels are ready to exit, false otherwise. func (l *LSMTree) checkAndTriggerCompaction() bool { readyToExit := true for idx, level := range l.levels { level.mu.RLock() if len(level.sstables) > maxLevelSSTables[idx] { l.compactionChan <- idx readyToExit = false } level.mu.RUnlock() } return readyToExit }")
Compacting a Level
When a compaction task is initiated for a level, follow these steps:
Acquire a Read Lock on the level to safely check if the compaction is needed by checking if the SSTable count surpasses the predefined limit for that level. Importantly, acquiring a read lock does not interfere with other read operations, such as
GetandRangeScan, which can continue to access the level concurrently.If compaction is required, obtain iterators for each SSTable within the level, positioned at their respective starting points.
Once iterators for all relevant SSTables have been acquired, it is safe to release the read lock. Given that SSTables are immutable - since they are not modified post-creation except by the compaction processes - and that this compaction function operates in a single-threaded manner, the integrity of the iterators is assured for the duration of the compaction task.
Merge SSTables by iterating through all SSTables in the level, merging their contents into a new SSTable. This process involves reading the key-value pairs in order (while preserving the latest version of each entry) and writing them into a new SSTable. We will discuss the intricacies of this merge iteration in detail in the following sections.
Acquire a write lock on the compacted level, as well as its subsequent level. This is important since the deletion of old SSTables and the introduction of the newly created SSTable should be atomic from the rest of the system’s viewpoint.
Delete old SSTables after the merge is complete to reclaim space. Following the successful merge into a new SSTable, the original, now-redundant SSTables can safely be deleted.
Add the newly created SSTable to the subsequent level of the LSM Tree. Additionally, log this compaction event to the
compactionChan, which may trigger further compaction tasks if the addition of the new SSTable causes the next level to exceed its own SSTable capacity limit.Finally, release both the write locks.
![// Compact the SSTables in the compaction candidate level. func (l *LSMTree) compactLevel(compactionCandidate int) error { if compactionCandidate == maxLevels-1 { // We don't need to compact the SSTables in the last level. return nil } // Lock the level while we check if we need to compact it. l.levels[compactionCandidate].mu.RLock() // Check if the number of SSTables in this level is less than the limit. // If yes, we don't need to compact this level. if len(l.levels[compactionCandidate].sstables) < maxLevelSSTables[compactionCandidate] { l.levels[compactionCandidate].mu.RUnlock() return nil } // 1. First get iterators for all the SSTables in this level. _, iterators := l.getSSTableHandlesAtLevel(compactionCandidate) // We can release the lock on the level now while we process the SSTables. This // is safe because these SSTables are immutable, and can only be deleted by // this function (which is single-threaded). l.levels[compactionCandidate].mu.RUnlock() // 2. Merge all the SSTables into a new SSTable. mergedSSTable, err := l.mergeSSTables(iterators, compactionCandidate+1) if err != nil { return err } l.levels[compactionCandidate].mu.Lock() l.levels[compactionCandidate+1].mu.Lock() // 3. Delete the old SSTables. l.deleteSSTablesAtLevel(compactionCandidate, iterators) // 4. Add the new SSTable to the next level. l.addSSTableToLevel(mergedSSTable, compactionCandidate+1) l.levels[compactionCandidate].mu.Unlock() l.levels[compactionCandidate+1].mu.Unlock() return nil } // Runs a merge on the iterators and creates a new SSTable from the merged // entries. func (l *LSMTree) mergeSSTables(iterators []*SSTableIterator, targetLevel int) (*SSTable, error) { mergedEntries := mergeIterators(iterators) sstableFileName := l.getSSTableFilename(targetLevel) sst, err := SerializeToSSTable(mergedEntries, sstableFileName) if err != nil { return nil, err } return sst, nil } // Get the SSTables and iterators for the SSTables at the level. Not thread-safe. func (l *LSMTree) getSSTableHandlesAtLevel(level int) ([]*SSTable, []*SSTableIterator) { sstables := l.levels[level].sstables iterators := make([]*SSTableIterator, len(sstables)) for i, sstable := range sstables { iterators[i] = sstable.Front() } return sstables, iterators } // Delete the SSTables identified by the iterators. Not thread-safe func (l *LSMTree) deleteSSTablesAtLevel(level int, iterators []*SSTableIterator) { l.levels[level].sstables = l.levels[level].sstables[len(iterators):] for _, it := range iterators { // Delete the file pointed to by the iterator. if err := os.Remove(it.s.file.Name()); err != nil { panic(err) } } } // Add an SSTable to the level. Not thread-safe. func (l *LSMTree) addSSTableToLevel(sst *SSTable, level int) { l.levels[level].sstables = append(l.levels[level].sstables, sst) // Send a signal on the compactionChan to indicate that a new SSTable has // been created. l.compactionChan <- level }](https://substackcdn.com/image/fetch/$s_!Mw4d!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fe39357bd-6b86-409b-904f-e6c0ad0ff39f_3680x7824.png "// Compact the SSTables in the compaction candidate level. func (l *LSMTree) compactLevel(compactionCandidate int) error { if compactionCandidate == maxLevels-1 { // We don't need to compact the SSTables in the last level. return nil } // Lock the level while we check if we need to compact it. l.levels[compactionCandidate].mu.RLock() // Check if the number of SSTables in this level is less than the limit. // If yes, we don't need to compact this level. if len(l.levels[compactionCandidate].sstables) < maxLevelSSTables[compactionCandidate] { l.levels[compactionCandidate].mu.RUnlock() return nil } // 1. First get iterators for all the SSTables in this level. _, iterators := l.getSSTableHandlesAtLevel(compactionCandidate) // We can release the lock on the level now while we process the SSTables. This // is safe because these SSTables are immutable, and can only be deleted by // this function (which is single-threaded). l.levels[compactionCandidate].mu.RUnlock() // 2. Merge all the SSTables into a new SSTable. mergedSSTable, err := l.mergeSSTables(iterators, compactionCandidate+1) if err != nil { return err } l.levels[compactionCandidate].mu.Lock() l.levels[compactionCandidate+1].mu.Lock() // 3. Delete the old SSTables. l.deleteSSTablesAtLevel(compactionCandidate, iterators) // 4. Add the new SSTable to the next level. l.addSSTableToLevel(mergedSSTable, compactionCandidate+1) l.levels[compactionCandidate].mu.Unlock() l.levels[compactionCandidate+1].mu.Unlock() return nil } // Runs a merge on the iterators and creates a new SSTable from the merged // entries. func (l *LSMTree) mergeSSTables(iterators []*SSTableIterator, targetLevel int) (*SSTable, error) { mergedEntries := mergeIterators(iterators) sstableFileName := l.getSSTableFilename(targetLevel) sst, err := SerializeToSSTable(mergedEntries, sstableFileName) if err != nil { return nil, err } return sst, nil } // Get the SSTables and iterators for the SSTables at the level. Not thread-safe. func (l *LSMTree) getSSTableHandlesAtLevel(level int) ([]*SSTable, []*SSTableIterator) { sstables := l.levels[level].sstables iterators := make([]*SSTableIterator, len(sstables)) for i, sstable := range sstables { iterators[i] = sstable.Front() } return sstables, iterators } // Delete the SSTables identified by the iterators. Not thread-safe func (l *LSMTree) deleteSSTablesAtLevel(level int, iterators []*SSTableIterator) { l.levels[level].sstables = l.levels[level].sstables[len(iterators):] for _, it := range iterators { // Delete the file pointed to by the iterator. if err := os.Remove(it.s.file.Name()); err != nil { panic(err) } } } // Add an SSTable to the level. Not thread-safe. func (l *LSMTree) addSSTableToLevel(sst *SSTable, level int) { l.levels[level].sstables = append(l.levels[level].sstables, sst) // Send a signal on the compactionChan to indicate that a new SSTable has // been created. l.compactionChan <- level }")
The design of the compaction process in our storage engine minimizes lock contention to uphold high concurrency across the system. We ensure that locks are held for the shortest time necessary. Locks on the levels array are acquired solely for the preliminary checks and the setup phase of the compaction process, primarily to determine whether compaction is necessary and to secure iterators for each SSTable in the target level. This approach ensures that the potentially time-consuming task of compaction itself occurs outside these critical sections. The reading of data from immutable SSTables and the merging of this data into a new SSTable - takes place without holding any locks on the system's critical structures.
This strategy significantly reduces the risk of lock contention, allowing other operations (e.g., read and write operations) to proceed uninterrupted.
The Merge Iteration
The merge operation during compaction in our LSM Tree uses the K-Way Merge Algorithm that we explored in depth while discussing range scans in a previous issue. Given the similarity between a compaction run and a range scan - the former simply being a special case of the latter in the form of a range scan across all entries in all the SSTables at a given level - it's beneficial to revisit our discussion of the K-Way Merge Algorithm's mechanics if its details have grown less familiar.

In the above code, we called the mergeIterators function to merge all the entries of the SSTables associated with the SSTableIterators we were holding.
![// Performs a k-way merge on SSTable iterators of possibly overlapping ranges // and merges them into a single range without any duplicate entries. // Deduplication is done by keeping track of the most recent entry for each key // and discarding the older ones using the timestamp. func mergeIterators(iterators []*SSTableIterator) []*LSMEntry { minHeap := &mergeHeap{} heap.Init(minHeap) var results []*LSMEntry // Keep track of the most recent entry for each key, in sorted order of keys. seen := skiplist.New(skiplist.String) // Add the iterators to the heap. for _, iterator := range iterators { if iterator == nil { continue } heap.Push(minHeap, heapEntry{entry: iterator.Value, iterator: iterator}) } for minHeap.Len() > 0 { // Pop the min entry from the heap. minEntry := heap.Pop(minHeap).(heapEntry) previousValue := seen.Get(minEntry.entry.Key) // Check if this key has been seen before. if previousValue != nil { // If the previous entry has a smaller timestamp, then we need to // replace it with the more recent entry. if previousValue.Value.(heapEntry).entry.Timestamp < minEntry.entry.Timestamp { seen.Set(minEntry.entry.Key, minEntry) } } else { // Add the entry to the seen list. seen.Set(minEntry.entry.Key, minEntry) } // Add the next element from the same list to the heap if minEntry.iterator.Next() != nil { nextEntry := minEntry.iterator.Value heap.Push(minHeap, heapEntry{entry: nextEntry, iterator: minEntry.iterator}) } } // Iterate through the seen list and add the values to the results. iter := seen.Front() for iter != nil { entry := iter.Value.(heapEntry) if entry.entry.Command == Command_DELETE { iter = iter.Next() continue } results = append(results, entry.entry) iter = iter.Next() } return results }](https://substackcdn.com/image/fetch/$s_!oJv6!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fd97415c0-2ad2-4e40-af3d-c9dd5a1cd8e5_3214x5388.png "// Performs a k-way merge on SSTable iterators of possibly overlapping ranges // and merges them into a single range without any duplicate entries. // Deduplication is done by keeping track of the most recent entry for each key // and discarding the older ones using the timestamp. func mergeIterators(iterators []*SSTableIterator) []*LSMEntry { minHeap := &mergeHeap{} heap.Init(minHeap) var results []*LSMEntry // Keep track of the most recent entry for each key, in sorted order of keys. seen := skiplist.New(skiplist.String) // Add the iterators to the heap. for _, iterator := range iterators { if iterator == nil { continue } heap.Push(minHeap, heapEntry{entry: iterator.Value, iterator: iterator}) } for minHeap.Len() > 0 { // Pop the min entry from the heap. minEntry := heap.Pop(minHeap).(heapEntry) previousValue := seen.Get(minEntry.entry.Key) // Check if this key has been seen before. if previousValue != nil { // If the previous entry has a smaller timestamp, then we need to // replace it with the more recent entry. if previousValue.Value.(heapEntry).entry.Timestamp < minEntry.entry.Timestamp { seen.Set(minEntry.entry.Key, minEntry) } } else { // Add the entry to the seen list. seen.Set(minEntry.entry.Key, minEntry) } // Add the next element from the same list to the heap if minEntry.iterator.Next() != nil { nextEntry := minEntry.iterator.Value heap.Push(minHeap, heapEntry{entry: nextEntry, iterator: minEntry.iterator}) } } // Iterate through the seen list and add the values to the results. iter := seen.Front() for iter != nil { entry := iter.Value.(heapEntry) if entry.entry.Command == Command_DELETE { iter = iter.Next() continue } results = append(results, entry.entry) iter = iter.Next() } return results }")
The only difference between this implementation and the mergeRanges() implementation of the k-way merge algorithm is the fact that the mergeRanges() method takes a list a list of ranges, while the mergeIterator method takes in a list of lightweight iterators to merge.
Since SSTables can grow to several gigabytes in size, it is impractical to preload all their entries into memory for the merging process. Instead, iterators are used to traverse through SSTable entries. These iterators maintain only the current entry in memory, significantly reducing the memory footprint of the compaction operation. This approach ensures that our system can efficiently handle large volumes of entries from the on-disk tables without compromising performance due to excessive memory consumption.
I would encourage the reader to implement a similar iterator for the Memtable and use a similarly optimized approach to service range scans as well.
Crash Recovery
Most LSM Tree implementations use a Write-Ahead Log (WAL) to recover from unexpected crashes. We discussed the functioning and internals of a Write-Ahead Log in a previous issue.

Every mutation to our storage engine’s state, be it an insert, update, or delete operation, is first recorded in the WAL. Only after this logging can the change be applied to the Memtable. This approach ensures that should the system encounter a failure before the Memtable is flushed to disk, all recent mutations not yet persisted in SSTables can be recovered from the WAL during the system's recovery process.
Once the memtable is flushed to the disk, we create a checkpoint in the WAL to indicate that all the entries up till this point are durably stored.
For our storage engine, we will integrate the WAL implementation discussed in a previous issue. While this WAL implementation may not represent the pinnacle of robustness or performance compared to industry standards, it serves our educational and developmental purposes well enough. Utilizing our own WAL code allows us to "dogfood" the code we wrote, providing valuable insights into the potential areas for improvement in our implementations.
You can find the code for the write-ahead log here.
Integrating the WAL with the LSM Tree
Open
Integrating the Write-Ahead Log storage engine begins with the Open() method, which initializes a new instance of our embedded database. We need to incorporate two operations into this method:
Initializing the Write-Ahead Log.
Recovering from the Write-Ahead Log: Recover any entries that might have been lost due to a system crash or an unexpected shutdown. These entries would have been written to the WAL but not yet persisted to an SSTable through the Memtable flush process. Recovery involves reading the WAL entries and replaying them to restore the database to its last known consistent state.
To facilitate these operations, we introduce a new parameter into the Open() method: recoverFromWAL. This boolean parameter allows the database administrator to specify whether the database should attempt to recover entries from the previously written WAL upon startup.
 (*LSMTree, error) { ctx, cancel := context.WithCancel(context.Background()) // Setup the WAL for the LSMTree. wal, err := gw.OpenWAL(directory+WALDirectorySuffix, true, 128000, 1000) if err != nil { cancel() return nil, err } ... lsm := &LSMTree{ ... } ... go lsm.backgroundMemtableFlushing() // Recover any entries that were written to the WAL but not flushed to // SSTables. if recoverFromWAL { if err := lsm.recoverFromWAL(); err != nil { return nil, err } } return lsm, nil }")
We initialize a WAL instance with the following properties:
We enable
fsyncto ensure high durability.We set the maximum on-disk WAL segment file size to 128KB.
We limit the maximum number of segments to be preserved by the WAL to 1000.
These parameters will usually be configured to match your workload, the values I am using are more or less arbitrary.
Before we dive into how the recoverFromWAL() method works, let’s understand how we are logging mutation operations such as Put() and Delete() into the WAL.
Put
![func (l *LSMTree) Put(key string, value []byte) error { l.mu.Lock() defer l.mu.Unlock() // Write to WAL before writing to memtable. We don't need to write to WAL // while recovering from WAL. if !l.inRecovery { l.wal.WriteEntry(mustMarshal(&WALEntry{ Key: key, Command: Command_PUT, Value: value, Timestamp: time.Now().UnixNano(), })) } ... return nil }](https://substackcdn.com/image/fetch/$s_!FOYg!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F3f04d5d7-4e80-4a77-af62-c6a4e40ebef8_2856x1944.png "func (l *LSMTree) Put(key string, value []byte) error { l.mu.Lock() defer l.mu.Unlock() // Write to WAL before writing to memtable. We don't need to write to WAL // while recovering from WAL. if !l.inRecovery { l.wal.WriteEntry(mustMarshal(&WALEntry{ Key: key, Command: Command_PUT, Value: value, Timestamp: time.Now().UnixNano(), })) } ... return nil }")
Once we have acquired a lock on the Memtable - we first append the key-value pair being inserted into the DB to the WAL.
We first check whether the system is “in recovery” by looking at the inRecovery field of the LSMTree. When the system initializes and begins to replay entries from the WAL during startup, it sets the inRecovery field to true (as we will see later). This step ensures the system recognizes it's in the recovery phase, not the normal operation mode. The primary function of the inRecovery field is to prevent the replayed operations from being logged again into the WAL. This safeguard helps avoid the creation of duplicate entries and the potential for an infinite loop, where entries are continuously written to the WAL as they are replayed.
We record four properties for each Put:
Key: The identifier for the data item being inserted or updated.Command: Indicates the operation type, in this case, aPut.Value: The actual data associated with the key.Timestamp: A unique identifier for the operation, used to determine the most recent update.
Once this information is securely logged in the WAL, the system proceeds with the regular Put operation flow.
Delete
 Delete(key string) error { l.mu.Lock() defer l.mu.Unlock() // Write to WAL before writing to memtable. We don't need to write to WAL // while recovering from WAL. if !l.inRecovery { l.wal.WriteEntry(mustMarshal(&WALEntry{ Key: key, Command: Command_DELETE, Timestamp: time.Now().UnixNano(), })) } ... return nil }")
Logging deletes to the WAL is almost identical to the Put flow. The only difference is that the Command is set to Delete, and the Value field is left empty.
Creating checkpoints
![// Flush a memtable to an on-disk SSTable. func (l *LSMTree) flushMemtable(memtable *Memtable) { ... l.levels[0].mu.Lock() l.flushingQueueMu.Lock() l.wal.CreateCheckpoint(mustMarshal(&WALEntry{ Key: sstableFileName, Command: Command_WRITE_SST, Timestamp: time.Now().UnixNano(), })) l.levels[0].sstables = append(l.levels[0].sstables, sst) l.flushingQueue = l.flushingQueue[1:] ... }](https://substackcdn.com/image/fetch/$s_!yyXo!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fc9ce5cb2-b71e-4666-b885-c4533b18430c_2246x2028.png "// Flush a memtable to an on-disk SSTable. func (l *LSMTree) flushMemtable(memtable *Memtable) { ... l.levels[0].mu.Lock() l.flushingQueueMu.Lock() l.wal.CreateCheckpoint(mustMarshal(&WALEntry{ Key: sstableFileName, Command: Command_WRITE_SST, Timestamp: time.Now().UnixNano(), })) l.levels[0].sstables = append(l.levels[0].sstables, sst) l.flushingQueue = l.flushingQueue[1:] ... }")
After the Memtable is successfully flushed to an SSTable, a checkpoint is created in the WAL. This checkpoint signifies that all entries logged up to this point have been safely persisted to disk.
During recovery, the system uses this checkpoint to determine which entries do not need to be replayed, as they are already secured in an SSTable. This ensures an efficient recovery process by only replaying the necessary entries that were not part of the flushed Memtable.
Recovery
![// Recover from the WAL. Read all entries from the WAL, after the last // checkpoint. This will give us all the entries that were written to the // memtable but not flushed to SSTables. func (l *LSMTree) recoverFromWAL() error { l.inRecovery = true defer func() { l.inRecovery = false }() // Read all entries from WAL, after the last checkpoint. This will give us // all the entries that were written to the memtable but not flushed to // SSTables. entries, err := l.readEntriesFromWAL() if err != nil { return err } for _, entry := range entries { if err := l.processWALEntry(entry); err != nil { return err } } return nil } func (l *LSMTree) readEntriesFromWAL() ([]*gw.WAL_Entry, error) { entries, err := l.wal.ReadAllFromOffset(-1, true) if err != nil { // Attempt to repair the WAL. _, err = l.wal.Repair() if err != nil { return nil, err } entries, err = l.wal.ReadAllFromOffset(-1, true) if err != nil { return nil, err } } return entries, nil } // Process a WAL entry. This function is used to recover from the WAL. // It reads the WAL entry and performs the corresponding operation on the // LSMTree. func (l *LSMTree) processWALEntry(entry *gw.WAL_Entry) error { if entry.GetIsCheckpoint() { // We may use this entry in the future to recover from more sophisticated // failures. return nil } walEntry := &WALEntry{} mustUnmarshal(entry.GetData(), walEntry) switch walEntry.Command { case Command_PUT: return l.Put(walEntry.Key, walEntry.Value) case Command_DELETE: return l.Delete(walEntry.Key) case Command_WRITE_SST: return errors.New("unexpected write sst command in WAL") default: return errors.New("unknown command in WAL") } }](https://substackcdn.com/image/fetch/$s_!6Ldb!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F266be421-295c-4820-bf0b-8e239946f3fd_2927x5808.png "// Recover from the WAL. Read all entries from the WAL, after the last // checkpoint. This will give us all the entries that were written to the // memtable but not flushed to SSTables. func (l *LSMTree) recoverFromWAL() error { l.inRecovery = true defer func() { l.inRecovery = false }() // Read all entries from WAL, after the last checkpoint. This will give us // all the entries that were written to the memtable but not flushed to // SSTables. entries, err := l.readEntriesFromWAL() if err != nil { return err } for _, entry := range entries { if err := l.processWALEntry(entry); err != nil { return err } } return nil } func (l *LSMTree) readEntriesFromWAL() ([]*gw.WAL_Entry, error) { entries, err := l.wal.ReadAllFromOffset(-1, true) if err != nil { // Attempt to repair the WAL. _, err = l.wal.Repair() if err != nil { return nil, err } entries, err = l.wal.ReadAllFromOffset(-1, true) if err != nil { return nil, err } } return entries, nil } // Process a WAL entry. This function is used to recover from the WAL. // It reads the WAL entry and performs the corresponding operation on the // LSMTree. func (l *LSMTree) processWALEntry(entry *gw.WAL_Entry) error { if entry.GetIsCheckpoint() { // We may use this entry in the future to recover from more sophisticated // failures. return nil } walEntry := &WALEntry{} mustUnmarshal(entry.GetData(), walEntry) switch walEntry.Command { case Command_PUT: return l.Put(walEntry.Key, walEntry.Value) case Command_DELETE: return l.Delete(walEntry.Key) case Command_WRITE_SST: return errors.New(\"unexpected write sst command in WAL\") default: return errors.New(\"unknown command in WAL\") } }")
The recoverFromWAL() first sets the inRecovery field of the LSMTree to true. This action signals that the system is entering the recovery phase, preventing certain operations, such as logging into the WAL, which could complicate the recovery process. It then manages the recovery process in two main phases:
Phase 1: The first phase involves reading all entries from the WAL, with the
readFromCheckpointargument set totrue. Reading from the last checkpoint helps streamline the recovery process by only reading back entries that have not been persisted to disk in the form of SSTables.Phase 2: After loading the relevant entries into memory, the method proceeds to replay them. The
processWALEntry()method is used for this purpose. It iterates through each entry and invokes the correspondingLSMTreemethod (e.g.,PutorDelete) to accurately mutate the database state.
Error Handling and WAL Repair
In the event of an error during the recovery process, the method attempts an automatic WAL repair to salvage as much data as possible. After the repair, it tries to recover the entries again, aiming for maximum data retrieval and system integrity.
Conclusion
This issue marks the conclusion of our journey into building a database engine from Scratch. We explored each component of the system in detail, starting from a high-level architectural overview, and then zooming into each component in detail. We explored how to design efficient in-memory and on-disk structures, keeping memory usage under control, controlling read and write amplification, and finally enabling high durability.
The complete code is available at github.com/JyotinderSingh/goLSM.
Bonus - Benchmarking
We can’t simply claim high performance without running an actual benchmark. I ran the Yahoo Cloud Serving Benchmark on the system we designed and aggregated some results here.
Our system is written in Go, we used a Go port of this project by PingCap called go-ycsb.
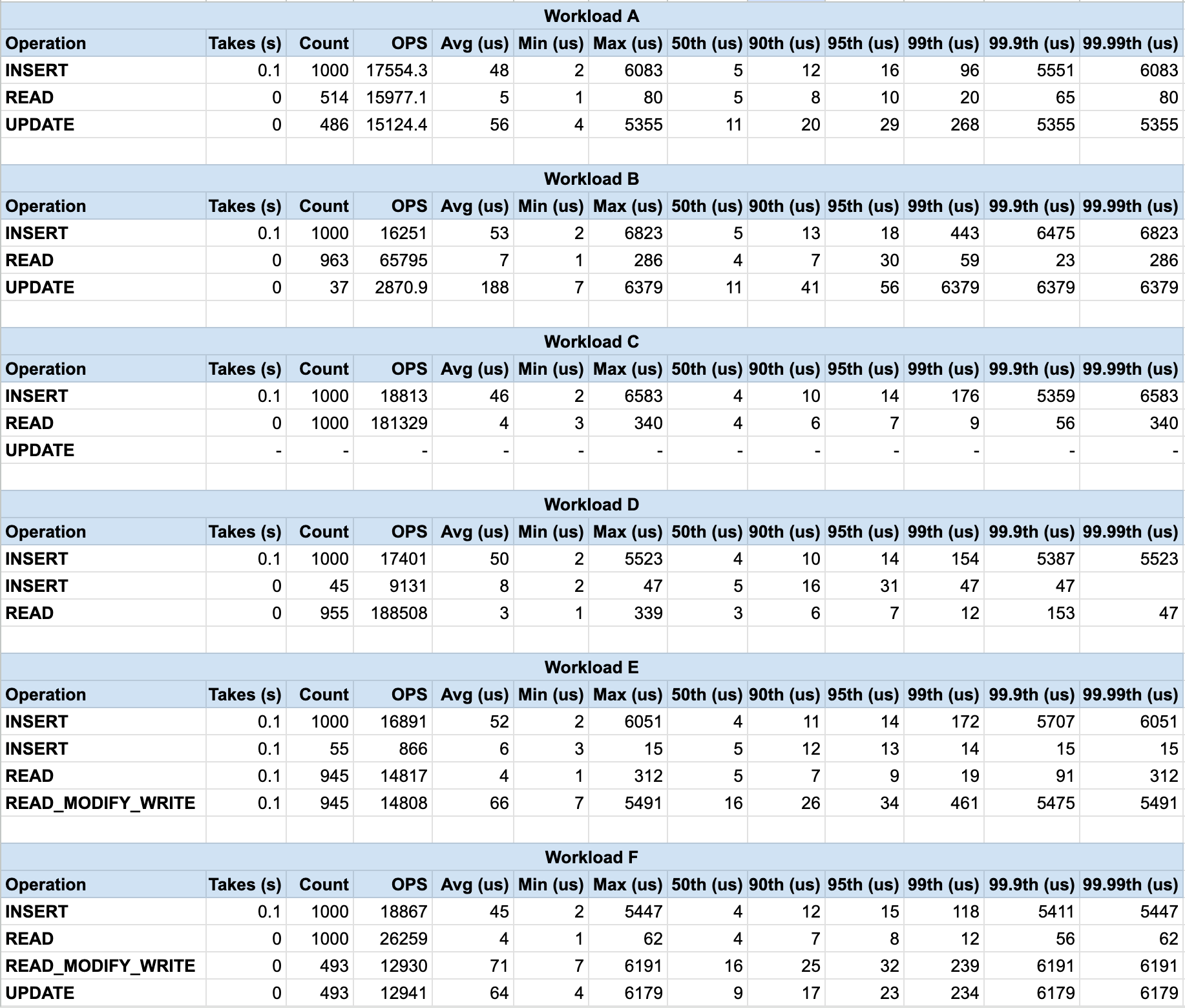
You can find the workload details here.
Analysis
Our storage engine seems to perform well for write-heavy workloads (A, D) and read-only workloads (C). However, there is room for improvement in workloads with a high read-modify-write ratio (F).
Positives
Fast Writes: Write operations (INSERT and UPDATE) across all workloads show low average latencies (around 50-70 microseconds). This suggests efficient handling of writes in the memtable.
Fast Reads in Read-Only Workload: Workload C (100% reads) shows excellent read performance with an average latency of around 4 microseconds. This indicates efficient retrieval from LSM-tree levels.
Areas for Improvement
Read-Modify-Write Performance: Workload F (read-modify-write) has a significantly higher average latency (around 70 microseconds) compared to simple reads (around 4 microseconds). This suggests potential overhead in retrieving data from lower levels for modification.
The high standard deviation in some workloads (especially the writes in Workload A) is probably caused by compaction and memtable flushing.
Overall, our LSM-Tree implementation seems well-suited for write-heavy and read-only workloads. However, some optimizations could me made for workloads involving frequent read-modify-write operations.
The code to run this benchmark on our database is available at github.com/JyotinderSingh/go-ycsb-go-lsm.