

Building a Write-Optimized Database Engine: Orchestrating Reads and Writes (Part 4)
Exploring how Memtables and SSTables fit into the low level architecture of our storage engine to support highly-concurrent reads and writes while enabling data durability.


In this issue, we dive into integrating the previously discussed Memtable and SSTable components to implement a cohesive storage engine. Our aim is to support high-throughput writes alongside consistent and efficient reads.
The Memtable functions as a high-speed, in-memory buffer, facilitating both incoming reads and writes. In contrast, the SSTable serves reads and provides a persistent, on-disk structure, ensuring data durability. While the high-level concepts of the design may appear straightforward, we will explore the complexities involved in managing the Memtable's flushing process. This includes handling filled Memtables while concurrently accepting new writes, which is critical to maintaining high throughput in our system. Additionally, we will explore how we can achieve consistent reads between the in-memory Memtables and on-disk SSTables. A major focus will be on the implementation of sophisticated locking mechanisms for transitioning Memtables, once filled and frozen, to their on-disk SSTable counterparts post-flush.
If you’d like to catch up on the previous issues, you can find them here.
The completed code we will be working towards is available on my GitHub. Given the scope of our discussions and the complexity of the storage engine implementation, we'll employ a variety of utility methods within our code snippets. To maintain the focus and brevity of our exploration, we will not get into the details of each utility method. However, for those eager to dive deeper into specific functions, the provided code is extensively commented to facilitate understanding.
Low-Level Architecture
LSM Tree
The LSMTree struct contains several fields. While we will explore the majority of these fields in the upcoming sections, topics such as Write-Ahead Logging recovery and Compaction are reserved for discussion in future issues.
![type level struct { sstables []*SSTable // SSTables in this level mu sync.RWMutex // [Lock 2]: for sstables in this level. } type KVPair struct { Key string Value []byte } type LSMTree struct { memtable *Memtable mu sync.RWMutex // [Lock 1]: for memtable. maxMemtableSize int64 // Maximum size of the memtable before it is flushed to an SSTable. directory string // Directory where the SSTables will be stored. wal *gw.WAL // WAL for LSMTree inRecovery bool // True if the LSMTree is recovering entries from WAL. levels []*level // SSTables in each level. current_sst_sequence uint64 // Sequence number for the next SSTable. compactionChan chan int // Channel for triggering compaction at a level. flushingQueue []*Memtable // Queue of memtables that need to be flushed to SSTables. flushingQueueMu sync.RWMutex // [Lock 3]: for flushingQueue. flushingChan chan *Memtable // Channel for triggering flushing of memtables to SSTables. ctx context.Context cancel context.CancelFunc wg sync.WaitGroup }](https://substackcdn.com/image/fetch/$s_!0STm!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fdd30e0d4-eea4-4f14-83ce-e04e5e1b56a3_3931x2616.png "type level struct { sstables []*SSTable // SSTables in this level mu sync.RWMutex // [Lock 2]: for sstables in this level. } type KVPair struct { Key string Value []byte } type LSMTree struct { memtable *Memtable mu sync.RWMutex // [Lock 1]: for memtable. maxMemtableSize int64 // Maximum size of the memtable before it is flushed to an SSTable. directory string // Directory where the SSTables will be stored. wal *gw.WAL // WAL for LSMTree inRecovery bool // True if the LSMTree is recovering entries from WAL. levels []*level // SSTables in each level. current_sst_sequence uint64 // Sequence number for the next SSTable. compactionChan chan int // Channel for triggering compaction at a level. flushingQueue []*Memtable // Queue of memtables that need to be flushed to SSTables. flushingQueueMu sync.RWMutex // [Lock 3]: for flushingQueue. flushingChan chan *Memtable // Channel for triggering flushing of memtables to SSTables. ctx context.Context cancel context.CancelFunc wg sync.WaitGroup }")
A notable aspect of our LSMTree's design is the implementation of a multi-level locking mechanism, which is critical for maintaining data integrity and consistency in a concurrent environment. These locks are categorized into three distinct "levels," each annotated with a numerical identifier ranging from 1 to 3. This numbering is not arbitrary; it serves as a guideline for the sequence in which locks should be acquired when multiple locks are necessary. By adhering to this specified order, the system effectively mitigates the risk of deadlocks.
This lock hierarchy ensures that operations requiring access to a consistent view of multiple components of the LSM Tree can do so safely. For instance, a process may need to lock the active Memtable (level 1) before proceeding to lock the flushing queue (level 2) and eventually the disk-based SSTables (level 3) for a comprehensive operation such as a range scan. By mandating that these locks be acquired in ascending numerical order, the system avoids scenarios where two processes hold locks in a manner that could lead to a deadlock.1
The LSMTree structure includes a significant component known as the levels array, which is designed to store SSTables across different "levels" within the system. This array is required for implementing a future compaction strategy called Tiered Compaction. In Tiered Compaction, each level above 0 signifies a tier containing compacted SSTables, which is a method to efficiently manage and merge SSTables to improve read performance and reduce storage overhead.
In this issue, our focus will be confined to level-0 SSTables. These are the SSTables generated directly from flushing Memtables to disk, representing the first tier of persisted data within the LSM Tree. For the current stage of our implementation, it is sufficient to conceptualize the levels array as a one-dimensional array exclusively comprising these level-0 SSTables. We will explore this in greater detail in upcoming issues where we dive deeper into the compaction process.
Opening a database
![func Open(directory string, maxMemtableSize int64) (*LSMTree, error) { ctx, cancel := context.WithCancel(context.Background()) levels := make([]*level, maxLevels) for i := 0; i < maxLevels; i++ { levels[i] = &level{ sstables: make([]*SSTable, 0), } } lsm := &LSMTree{ memtable: NewMemtable(), maxMemtableSize: maxMemtableSize, directory: directory, inRecovery: false, current_sst_sequence: 0, levels: levels, compactionChan: make(chan int, 100), flushingQueue: make([]*Memtable, 0), flushingChan: make(chan *Memtable, 100), ctx: ctx, cancel: cancel, } if err := lsm.loadSSTables(); err != nil { return nil, err } lsm.wg.Add(1) go lsm.backgroundMemtableFlushing() return lsm, nil }](https://substackcdn.com/image/fetch/$s_!XU0L!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fa7fd514a-bf2d-4350-8269-bf6bf16f9586_2676x3204.png "func Open(directory string, maxMemtableSize int64) (*LSMTree, error) { ctx, cancel := context.WithCancel(context.Background()) levels := make([]*level, maxLevels) for i := 0; i < maxLevels; i++ { levels[i] = &level{ sstables: make([]*SSTable, 0), } } lsm := &LSMTree{ memtable: NewMemtable(), maxMemtableSize: maxMemtableSize, directory: directory, inRecovery: false, current_sst_sequence: 0, levels: levels, compactionChan: make(chan int, 100), flushingQueue: make([]*Memtable, 0), flushingChan: make(chan *Memtable, 100), ctx: ctx, cancel: cancel, } if err := lsm.loadSSTables(); err != nil { return nil, err } lsm.wg.Add(1) go lsm.backgroundMemtableFlushing() return lsm, nil }")
The Open method initializes a single instance of our key-value store. For now, it only takes in two parameters:
directory: The directory in which the database files should be stored. It uniquely identifies the embedded database instance in its local directory.maxMemtableSize: The maximum allowed size till which the in-memory memtable can grow before being flushed.
In addition to initializing the LSMTree instance and different levels of SSTables in the levels array we do two things:
loadSSTables(): We look for any previously persisted SSTables in the database directory and load their metadata into memory. We have already discussed how theOpenSSTable()method works in the previous issue.![// Loads all the SSTables from disk into memory. Also sorts the SSTables by // sequence number. This function should be called on startup. func (l *LSMTree) loadSSTables() error { if err := os.MkdirAll(l.directory, 0755); err != nil { return err } if err := l.loadSSTablesFromDisk(); err != nil { return err } l.sortSSTablesBySequenceNumber() // Get the sequence number of the latest SSTable persisted to the disk. l.initializeCurrentSequenceNumber() return nil } // Load SSTables from disk. Loads all files in the directory that have the // SSTable prefix. func (l *LSMTree) loadSSTablesFromDisk() error { files, err := os.ReadDir(l.directory) if err != nil { return err } for _, file := range files { if file.IsDir() || !isSSTableFile(file.Name()) { continue } sstable, err := OpenSSTable(l.directory + "/" + file.Name()) if err != nil { return err } level := l.getLevelFromSSTableFilename(sstable.file.Name()) l.levels[level].sstables = append(l.levels[level].sstables, sstable) } return nil }](https://substackcdn.com/image/fetch/$s_!9JGl!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fd09a6449-da8a-46a1-9657-e2da5bd78148_2856x3876.png "// Loads all the SSTables from disk into memory. Also sorts the SSTables by // sequence number. This function should be called on startup. func (l *LSMTree) loadSSTables() error { if err := os.MkdirAll(l.directory, 0755); err != nil { return err } if err := l.loadSSTablesFromDisk(); err != nil { return err } l.sortSSTablesBySequenceNumber() // Get the sequence number of the latest SSTable persisted to the disk. l.initializeCurrentSequenceNumber() return nil } // Load SSTables from disk. Loads all files in the directory that have the // SSTable prefix. func (l *LSMTree) loadSSTablesFromDisk() error { files, err := os.ReadDir(l.directory) if err != nil { return err } for _, file := range files { if file.IsDir() || !isSSTableFile(file.Name()) { continue } sstable, err := OpenSSTable(l.directory + \"/\" + file.Name()) if err != nil { return err } level := l.getLevelFromSSTableFilename(sstable.file.Name()) l.levels[level].sstables = append(l.levels[level].sstables, sstable) } return nil }")
backgroundMemtableFlushing(): A separate goroutine that manages Memtable flushing in the background. We will discuss this in more detail in the upcoming sections.

![// Loads all the SSTables from disk into memory. Also sorts the SSTables by // sequence number. This function should be called on startup. func (l *LSMTree) loadSSTables() error { if err := os.MkdirAll(l.directory, 0755); err != nil { return err } if err := l.loadSSTablesFromDisk(); err != nil { return err } l.sortSSTablesBySequenceNumber() // Get the sequence number of the latest SSTable persisted to the disk. l.initializeCurrentSequenceNumber() return nil } // Load SSTables from disk. Loads all files in the directory that have the // SSTable prefix. func (l *LSMTree) loadSSTablesFromDisk() error { files, err := os.ReadDir(l.directory) if err != nil { return err } for _, file := range files { if file.IsDir() || !isSSTableFile(file.Name()) { continue } sstable, err := OpenSSTable(l.directory + "/" + file.Name()) if err != nil { return err } level := l.getLevelFromSSTableFilename(sstable.file.Name()) l.levels[level].sstables = append(l.levels[level].sstables, sstable) } return nil }](https://substackcdn.com/image/fetch/$s_!9JGl!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fd09a6449-da8a-46a1-9657-e2da5bd78148_2856x3876.png "// Loads all the SSTables from disk into memory. Also sorts the SSTables by // sequence number. This function should be called on startup. func (l *LSMTree) loadSSTables() error { if err := os.MkdirAll(l.directory, 0755); err != nil { return err } if err := l.loadSSTablesFromDisk(); err != nil { return err } l.sortSSTablesBySequenceNumber() // Get the sequence number of the latest SSTable persisted to the disk. l.initializeCurrentSequenceNumber() return nil } // Load SSTables from disk. Loads all files in the directory that have the // SSTable prefix. func (l *LSMTree) loadSSTablesFromDisk() error { files, err := os.ReadDir(l.directory) if err != nil { return err } for _, file := range files { if file.IsDir() || !isSSTableFile(file.Name()) { continue } sstable, err := OpenSSTable(l.directory + \"/\" + file.Name()) if err != nil { return err } level := l.getLevelFromSSTableFilename(sstable.file.Name()) l.levels[level].sstables = append(l.levels[level].sstables, sstable) } return nil }")
From the start
Upon the initial startup of the database engine, it begins in a pristine state, without any data and lacking any on-disk components. At this stage, the only available structure is an in-memory Memtable, ready to receive writes. This is where we begin our journey.
Our goal is to devise a strategy that allows for continuous writes into this Memtable, up until it reaches its maximum capacity. Once this limit is met, the next step involves “freezing” the Memtable, making it immutable, and flushing its contents to disk, ensuring no new write requests are processed until this operation is complete. Following a successful flush, the Memtable is cleared, making it ready to accept new writes. The APIs required for extracting entries from the Memtable and serializing them into an SSTable have already been discussed in previous issues.
While this approach is fundamentally okay, it introduces a significant bottleneck. The process of flushing the Memtable to disk involves locking the in-memory table and performing disk I/O (an inherently slow operation). As a result, the database engine must pause all read and write operations during the flush, presenting an obvious challenge for a system designed to optimize for high write throughput.
We need to find a better way.
Memtable Flushing Queue
A better strategy to manage Memtable flushes involves maintaining a distinct queue that stores filled and frozen Memtables awaiting disk flush.
When a Memtable reaches its capacity and is subsequently “frozen”, it is transferred to this flushing queue. This allows the system to introduce a new, empty Memtable ready to accommodate incoming writes. It's important to highlight that even while in the flushing queue, these frozen Memtables continue to service read requests, ensuring that data remains accessible until it has been successfully persisted to disk. This ensures that the system can keep accepting new writes without interruption, effectively decoupling the storage engine’s write process from the slower disk I/O operations involved in flushing. Once a Memtable's contents are fully flushed to disk, it can be safely removed from the queue.
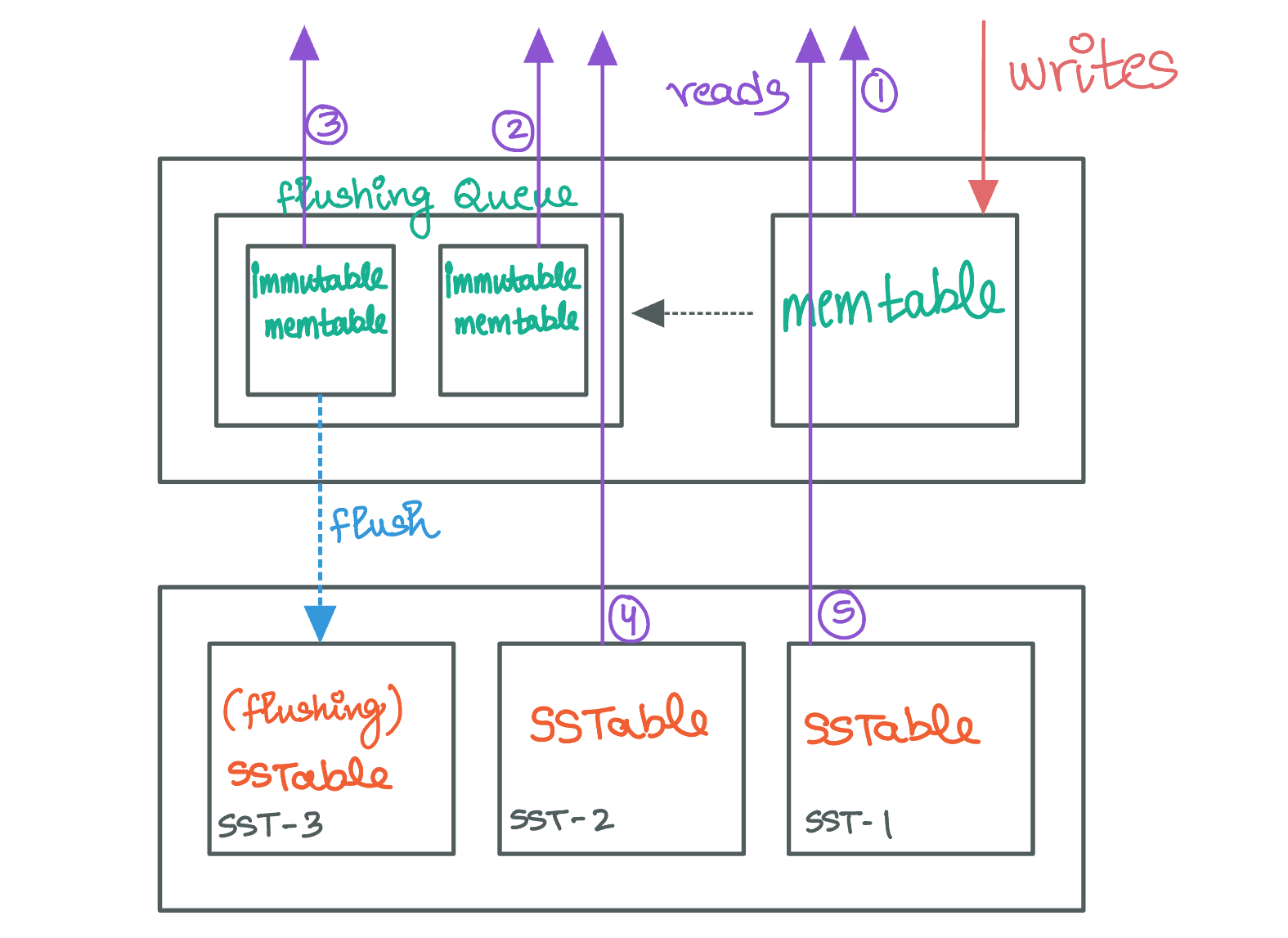
The active Memtable continues to accept writes, operating alongside the filled-up, immutable Memtables queued for disk flushing. Each Memtable in this queue targets a specific SSTable index on the disk based on their order in the queue.
For read operations, the process begins with the active Memtable. If the desired key is not found there, the search progresses to the Memtables in the flushing queue. This search occurs in reverse order of their insertion to prioritize newer data. This ensures that read requests are resolved using the most up-to-date in-memory data before resorting to disk-based storage.
Should the search through the active Memtable and the flushing queue prove unsuccessful, the system then queries the on-disk SSTables. This search starts with the newest SSTables and moves towards the oldest, following the principle that recent data is most relevant. One should note that the SSTable currently being written to (the flush-target SSTable) is excluded from read operations since it is incomplete. Additionally, any key sought from this SSTable should still be accessible from its in-memory counterpart in the flushing queue.
Now that we understand the write path, it’s time to implement it.
Inserts
![// Insert a key-value pair into the LSMTree. func (l *LSMTree) Put(key string, value []byte) error { l.mu.Lock() defer l.mu.Unlock() l.memtable.Put(key, value) // Check if the memtable has exceeded the maximum size and // needs to be flushed to an SSTable. if l.memtable.SizeInBytes() > l.maxMemtableSize { l.flushingQueueMu.Lock() l.flushingQueue = append(l.flushingQueue, l.memtable) l.flushingQueueMu.Unlock() l.flushingChan <- l.memtable l.memtable = NewMemtable() } return nil }](https://substackcdn.com/image/fetch/$s_!o5nV!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F71d3c707-78c8-40c9-aedb-7c890dc2dfbd_2354x2028.png "// Insert a key-value pair into the LSMTree. func (l *LSMTree) Put(key string, value []byte) error { l.mu.Lock() defer l.mu.Unlock() l.memtable.Put(key, value) // Check if the memtable has exceeded the maximum size and // needs to be flushed to an SSTable. if l.memtable.SizeInBytes() > l.maxMemtableSize { l.flushingQueueMu.Lock() l.flushingQueue = append(l.flushingQueue, l.memtable) l.flushingQueueMu.Unlock() l.flushingChan <- l.memtable l.memtable = NewMemtable() } return nil }")
The Put operation, at its core, is straightforward: we simply acquire a lock on the Memtable and insert the key-value pair provided by the caller. However, after the insert we need to ensure the Memtable has not exceeded its maximum allowable size. When this threshold is reached, we must transition the Memtable to a "frozen" state, where it no longer accepts new writes, and initiate its flush to disk. As discussed, this process is conducted asynchronously.
Initially, we lock the flushingQueue to safely modify its contents. We then append a pointer to the now-frozen Memtable into this queue. The queue ensures that the frozen Memtables remain accessible for read operations during their flush period. This ensures that the system can continue to serve read requests without interruption.
Furthermore, we push a pointer to the filled Memtable into a channel called flushingChan. This channel acts as a thread-safe queue for the background flush process, signaling it to begin the task of flushing the Memtable to disk. Following the successful enqueueing of the Memtable into both the queue and the channel, we proceed to instantiate a new, empty Memtable for the LSM Tree, effectively replacing the active one.
This transition allows the database to continue accepting write operations, thereby upholding high throughput.
Now it’s time to understand how the backgroundMemtableFlushing() method works.
Flushing Frozen Memtables
![// Continuously listen on flushingChan for memtables to flush. When a memtable // is received, flush it to an SSTable. When the context is cancelled, return. func (l *LSMTree) backgroundMemtableFlushing() error { defer l.wg.Done() for { select { case <-l.ctx.Done(): if len(l.flushingChan) == 0 { return nil } case memtable := <-l.flushingChan: l.flushMemtable(memtable) } } } // Flush a memtable to an on-disk SSTable. func (l *LSMTree) flushMemtable(memtable *Memtable) { if memtable.size == 0 { return } atomic.AddUint64(&l.current_sst_sequence, 1) sstableFileName := l.getSSTableFilename(0) sst, err := SerializeToSSTable(memtable.GetEntries(), sstableFileName) if err != nil { panic(err) } l.levels[0].mu.Lock() l.flushingQueueMu.Lock() l.levels[0].sstables = append(l.levels[0].sstables, sst) l.flushingQueue = l.flushingQueue[1:] l.flushingQueueMu.Unlock() l.levels[0].mu.Unlock() // Send a signal on the compactionChan to indicate that a new SSTable has // been created. l.compactionChan <- 0 }](https://substackcdn.com/image/fetch/$s_!4TvU!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fcc0b7559-9e24-4ddb-8cfd-0ccf752f9eee_2963x4128.png "// Continuously listen on flushingChan for memtables to flush. When a memtable // is received, flush it to an SSTable. When the context is cancelled, return. func (l *LSMTree) backgroundMemtableFlushing() error { defer l.wg.Done() for { select { case <-l.ctx.Done(): if len(l.flushingChan) == 0 { return nil } case memtable := <-l.flushingChan: l.flushMemtable(memtable) } } } // Flush a memtable to an on-disk SSTable. func (l *LSMTree) flushMemtable(memtable *Memtable) { if memtable.size == 0 { return } atomic.AddUint64(&l.current_sst_sequence, 1) sstableFileName := l.getSSTableFilename(0) sst, err := SerializeToSSTable(memtable.GetEntries(), sstableFileName) if err != nil { panic(err) } l.levels[0].mu.Lock() l.flushingQueueMu.Lock() l.levels[0].sstables = append(l.levels[0].sstables, sst) l.flushingQueue = l.flushingQueue[1:] l.flushingQueueMu.Unlock() l.levels[0].mu.Unlock() // Send a signal on the compactionChan to indicate that a new SSTable has // been created. l.compactionChan <- 0 }")
When initializing a database instance, we concurrently launched a background thread tasked with managing the Memtable flush process. This thread, through the backgroundMemtableFlushing() function, employs a for-select loop to monitor two signals:
Signal on the Done channel in its supplied context: This signal is an indicator that the database engine is in the process of shutting down, prompting the background thread to prepare for termination. However, an immediate exit is not always appropriate. The function first verifies whether the
flushingChanis empty. If the channel is empty, indicating no outstanding flush operations, the thread can safely terminate. Otherwise, the thread remains active, awaiting the clearance offlushingChanto ensure all Memtables are flushed to disk before shutting down.Presence of Memtables in the
flushingChan: Thefor-selectloop also listens for Memtables being pushed into theflushingChan. Upon detection, these Memtables are sequentially retrieved from the channel. Each Memtable extracted is then processed through theflushMemtable()method, which is responsible for flushing the Memtable's contents to disk, effectively converting it into an SSTable.
The flushMemtable() method starts by atomically incrementing the current_sst_sequence number. This prepares the system for the creation of a new SSTable, ensuring a unique sequence identifier for each SSTable generated. Following this, the method proceeds to retrieve the contents of the Memtable slated for flushing.
Utilizing the SerializeToSSTable() method, the contents of the Memtable are then serialized and written out as an SSTable. The internals of the SerializeToSSTable() method, including how it transforms Memtable data into the SSTable format, were discussed in the previous issue.
Upon successful completion of the SSTable flush, two operations must be conducted, in an atomic manner (with respect to the database’s logical view) to maintain consistency:
Incorporate the new SSTable into the zeroth level of the
levelsarray: This array, as previously mentioned, organizes SSTables across different tiers. Initially, all flushed SSTables are placed in the zeroth level, which houses newly created SSTables. The placement of an SSTable into this level signifies its readiness to serve read operations. Future issues will explore how SSTables progress through subsequent levels via the compaction process.Discard the flushed Memtable: With the new SSTable now capable of serving read requests, the corresponding Memtable, which temporarily continued to handle reads while in the
flushingQueue, can be safely removed.
Here's how the process unfolds:
Acquire Write-Locks: We begin by taking a write-lock on the zeroth index of the
levelsarray and another write-lock on theflushingQueue. This dual lock acquisition ensures exclusive access to these critical sections of the LSM tree, allowing for safe modifications. Adherence to our predefined lock ordering is essential here to avoid potential deadlocks, ensuring that locks are acquired in a consistent and deadlock-free manner.Insert SSTable Metadata into the
levelsArray: With the necessary locks in place, we insert the metadata of the newly flushed SSTable into the zeroth level of thelevelsarray. This action signifies that the SSTable is now ready to serve read operations and participate in future compaction processes.Remove the Flushed Memtable from the
flushingQueue: We remove the Memtable (residing at the zeroth index of theflushingQueue) that corresponds to the SSTable we just flushed.Release Locks: Following the successful execution of these operations, both the write-locks on the zeroth index of the
levelsarray and theflushingQueueare released.
Delete
 Delete(key string) error { l.mu.Lock() defer l.mu.Unlock() l.memtable.Delete(key) // Check if the memtable has exceeded the maximum size and needs to be flushed // to an SSTable. if l.memtable.SizeInBytes() > l.maxMemtableSize { l.flushingQueueMu.Lock() l.flushingQueue = append(l.flushingQueue, l.memtable) l.flushingQueueMu.Unlock() l.flushingChan <- l.memtable l.memtable = NewMemtable() } return nil }")
The Delete() method is identical to the Put() method, except for the fact that it calls the Delete() API on the Memtable.
Get
![func (l *LSMTree) Get(key string) ([]byte, error) { l.mu.RLock() value := l.memtable.Get(key) if value != nil { l.mu.RUnlock() return handleValue(value) } l.mu.RUnlock() // Check flushing queue memtables in reverse order. l.flushingQueueMu.RLock() for i := len(l.flushingQueue) - 1; i >= 0; i-- { value = l.flushingQueue[i].Get(key) if value != nil { l.flushingQueueMu.RUnlock() return handleValue(value) } } l.flushingQueueMu.RUnlock() // Iterate over all levels. for level := range l.levels { // Check SSTables at this level in reverse order. l.levels[level].mu.RLock() for i := len(l.levels[level].sstables) - 1; i >= 0; i-- { value, err := l.levels[level].sstables[i].Get(key) if err != nil { l.levels[level].mu.RUnlock() return nil, err } if value != nil { l.levels[level].mu.RUnlock() return handleValue(value) } } l.levels[level].mu.RUnlock() } return nil, nil }](https://substackcdn.com/image/fetch/$s_!-xm9!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fdd23efa2-31f5-4e6b-a136-f1c9a7cc4564_2354x3708.png "func (l *LSMTree) Get(key string) ([]byte, error) { l.mu.RLock() value := l.memtable.Get(key) if value != nil { l.mu.RUnlock() return handleValue(value) } l.mu.RUnlock() // Check flushing queue memtables in reverse order. l.flushingQueueMu.RLock() for i := len(l.flushingQueue) - 1; i >= 0; i-- { value = l.flushingQueue[i].Get(key) if value != nil { l.flushingQueueMu.RUnlock() return handleValue(value) } } l.flushingQueueMu.RUnlock() // Iterate over all levels. for level := range l.levels { // Check SSTables at this level in reverse order. l.levels[level].mu.RLock() for i := len(l.levels[level].sstables) - 1; i >= 0; i-- { value, err := l.levels[level].sstables[i].Get(key) if err != nil { l.levels[level].mu.RUnlock() return nil, err } if value != nil { l.levels[level].mu.RUnlock() return handleValue(value) } } l.levels[level].mu.RUnlock() } return nil, nil }")
The Get() method is a comprehensive operation that touches upon almost all of the intricacies of the LSM Tree’s design that we’ve discussed so far, aiming to retrieve the most recent version of a given key amidst potentially multiple versions scattered across the LSM tree's various components. The method employs a tiered search strategy to ensure data consistency. Here's a breakdown of how the Get() method operates:
Active Memtable: The search begins with the active Memtable, the most recent recipient of write operations. Given that it is the first line of write intake, the active Memtable is the place to contain the latest version of any given key.
Frozen Memtables in the Flushing Queue: If the key is not found in the active Memtable, the method proceeds to search through the frozen Memtables that are queued for flushing to disk. This search is conducted in reverse order of their insertion into the flushing queue, prioritizing Memtables that were most recently frozen. This is because the closer a Memtable is to the active state, the more recent its data is likely to be.
SSTables in
levels: Following the in-memory searches, if the key has still not been located, the search extends to the SSTables stored on disk. This search starts from level 0 SSTables, which are direct flushes from Memtables and thus contain the most recent on-disk data. The search then proceeds through the higher levels of SSTables, with each level representing a progressively older set of data due to the compaction process. Within each level, SSTables are searched in decreasing order of their indices, reflecting the chronological order in which they were created or compacted.
The Get() method's design leverages read locks to enhance concurrency across the system. The method does not require exclusive access to the entire data hierarchy for a single Get() operation. Instead, it adopts a sequential approach to lock acquisition and release, navigating through the active Memtable, the frozen Memtables in the flushing queue, and each level of the SSTable hierarchy in turn. This strategy is underpinned by a key insight into our LSM tree's operational dynamics:
Data within the LSM tree progresses linearly through its hierarchy, moving from the active Memtable to frozen Memtables, and eventually to SSTables across various levels due to flushing and compaction processes. This linear movement ensures that if data changes location (due to a write or compaction operation) after the Get() operation has begun, such changes will only propel the data further down the read path. Therefore, any data relevant to the Get() operation that has yet to be encountered will still be captured as the method progresses through its sequential search. This guarantees the method's ability to return the most recent version of a key without requiring a lock on the entire database structure simultaneously.
It also ensures that writes occurring parallel to a Get() operation do not interfere with the operation's outcome. Since new writes can only affect structures in the past of the Get() operation's progression through the LSM tree (since the read lock on the currently active read target prevents changes to that target and subsequently anything after that), they do not alter the search results of the ongoing Get() operation.
This locking mechanism thus safeguards the consistency of read operations while permitting a high degree of concurrent data access and manipulation within our storage engine.
RangeScan
![func (l *LSMTree) RangeScan(startKey string, endKey string) ([]KVPair, error) { ranges := [][]*LSMEntry{} // We take all locks together to ensure a consistent view of the LSMTree for // the range scan. l.mu.RLock() defer l.mu.RUnlock() // lock all levels for _, level := range l.levels { level.mu.RLock() defer level.mu.RUnlock() } l.flushingQueueMu.RLock() defer l.flushingQueueMu.RUnlock() entries := l.memtable.RangeScan(startKey, endKey) ranges = append(ranges, entries) // Check flushing queue memtables in reverse order. for i := len(l.flushingQueue) - 1; i >= 0; i-- { entries := l.flushingQueue[i].RangeScan(startKey, endKey) ranges = append(ranges, entries) } // Iterate through all levels. for _, level := range l.levels { // Check SSTables at this level in reverse order. for i := len(level.sstables) - 1; i >= 0; i-- { entries, err := level.sstables[i].RangeScan(startKey, endKey) if err != nil { return nil, err } ranges = append(ranges, entries) } } return mergeRanges(ranges), nil } // Performs a k-way merge on a list of possibly overlapping ranges and merges // them into a single range without any duplicate entries. // Deduplication is done by keeping track of the most recent entry for each key // and discarding the older ones using the timestamp. func mergeRanges(ranges [][]*LSMEntry) []KVPair { minHeap := &mergeHeap{} heap.Init(minHeap) var results []KVPair // Keep track of the most recent entry for each key, in sorted order of keys. seen := skiplist.New(skiplist.String) // Add the first element from each list to the heap. for i, entries := range ranges { if len(entries) > 0 { heap.Push(minHeap, heapEntry{entry: entries[0], listIndex: i, idx: 0}) } } for minHeap.Len() > 0 { // Pop the min entry from the heap. minEntry := heap.Pop(minHeap).(heapEntry) previousValue := seen.Get(minEntry.entry.Key) // Check if this key has been seen before. if previousValue != nil { // If the previous entry has a smaller timestamp, then we need to // replace it with the more recent entry. if previousValue.Value.(heapEntry).entry.Timestamp < minEntry.entry.Timestamp { seen.Set(minEntry.entry.Key, minEntry) } } else { // Add the entry to the seen list. seen.Set(minEntry.entry.Key, minEntry) } // Add the next element from the same list to the heap if minEntry.idx+1 < len(ranges[minEntry.listIndex]) { nextEntry := ranges[minEntry.listIndex][minEntry.idx+1] heap.Push(minHeap, heapEntry{entry: nextEntry, listIndex: minEntry.listIndex, idx: minEntry.idx + 1}) } } // Iterate through the seen list and add the values to the results. iter := seen.Front() for iter != nil { entry := iter.Value.(heapEntry) if entry.entry.Command == Command_DELETE { iter = iter.Next() continue } results = append(results, KVPair{Key: entry.entry.Key, Value: entry.entry.Value}) iter = iter.Next() } return results }](https://substackcdn.com/image/fetch/$s_!YKGL!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fb5984810-cbfb-4f7b-8ce1-cc33d5520089_3214x8580.png "func (l *LSMTree) RangeScan(startKey string, endKey string) ([]KVPair, error) { ranges := [][]*LSMEntry{} // We take all locks together to ensure a consistent view of the LSMTree for // the range scan. l.mu.RLock() defer l.mu.RUnlock() // lock all levels for _, level := range l.levels { level.mu.RLock() defer level.mu.RUnlock() } l.flushingQueueMu.RLock() defer l.flushingQueueMu.RUnlock() entries := l.memtable.RangeScan(startKey, endKey) ranges = append(ranges, entries) // Check flushing queue memtables in reverse order. for i := len(l.flushingQueue) - 1; i >= 0; i-- { entries := l.flushingQueue[i].RangeScan(startKey, endKey) ranges = append(ranges, entries) } // Iterate through all levels. for _, level := range l.levels { // Check SSTables at this level in reverse order. for i := len(level.sstables) - 1; i >= 0; i-- { entries, err := level.sstables[i].RangeScan(startKey, endKey) if err != nil { return nil, err } ranges = append(ranges, entries) } } return mergeRanges(ranges), nil } // Performs a k-way merge on a list of possibly overlapping ranges and merges // them into a single range without any duplicate entries. // Deduplication is done by keeping track of the most recent entry for each key // and discarding the older ones using the timestamp. func mergeRanges(ranges [][]*LSMEntry) []KVPair { minHeap := &mergeHeap{} heap.Init(minHeap) var results []KVPair // Keep track of the most recent entry for each key, in sorted order of keys. seen := skiplist.New(skiplist.String) // Add the first element from each list to the heap. for i, entries := range ranges { if len(entries) > 0 { heap.Push(minHeap, heapEntry{entry: entries[0], listIndex: i, idx: 0}) } } for minHeap.Len() > 0 { // Pop the min entry from the heap. minEntry := heap.Pop(minHeap).(heapEntry) previousValue := seen.Get(minEntry.entry.Key) // Check if this key has been seen before. if previousValue != nil { // If the previous entry has a smaller timestamp, then we need to // replace it with the more recent entry. if previousValue.Value.(heapEntry).entry.Timestamp < minEntry.entry.Timestamp { seen.Set(minEntry.entry.Key, minEntry) } } else { // Add the entry to the seen list. seen.Set(minEntry.entry.Key, minEntry) } // Add the next element from the same list to the heap if minEntry.idx+1 < len(ranges[minEntry.listIndex]) { nextEntry := ranges[minEntry.listIndex][minEntry.idx+1] heap.Push(minHeap, heapEntry{entry: nextEntry, listIndex: minEntry.listIndex, idx: minEntry.idx + 1}) } } // Iterate through the seen list and add the values to the results. iter := seen.Front() for iter != nil { entry := iter.Value.(heapEntry) if entry.entry.Command == Command_DELETE { iter = iter.Next() continue } results = append(results, KVPair{Key: entry.entry.Key, Value: entry.entry.Value}) iter = iter.Next() } return results }")
The RangeScan() method in an LSM tree-based storage engine is quite involved due to the need to fetch and then reconcile data from various storage structures within the database. This method extends beyond simple key-value lookups, requiring a comprehensive scan and merge of data across the entire storage hierarchy to ensure the retrieval of the latest and most relevant entries within a specified range.
Data Fetching
This initial step involves querying each storage structure—active Memtable, frozen Memtables in the flushing queue, and SSTables across all levels—similar to the Get() operation. The goal here is to gather all entries within the specified range from these structures. Given the LSM tree's design, data related to a particular key or within a range can reside in multiple places, necessitating a scan across all tiers.
Note that we acquire a lock on all these structures at the same time before we start reading - this is to ensure a consistent view of the data inside the database for the range scan to work with. This also means that a range scan is a heavy operation since it wrecks the concurrency for the entire database by locking every single storage structure. While there are ways to optimize this, however, they are quite involved and outside the scope of our discussion.
Data Reconciliation
Once data is fetched, the next challenge is to reconcile duplicate entries and consolidate the data into a coherent range without redundancies. This is achieved through a merging process, specifically using a k-way merge algorithm optimized for handling multiple intersecting ranges. The goal is to merge these ranges into a single, deduplicated range.
K-Way Merge Algorithm Explanation
The algorithm employs a min-heap to efficiently merge and deduplicate the entries from the intersecting ranges. In Go, we do not get an inbuilt heap data structure, instead, we need to implement the methods for the provided heap.Interface.
Heap Entry (
heapEntry): This structure represents an individual entry in the heap. It contains the LSM entry (entry) that this heap entry represents, an index to identify the source list (listIndex) in the given array of lists (ranges) to be merged, an index within that list (idx) to represent an individual element, and an iterator for SSTable entries (used when performing compaction).Merge Heap (
mergeHeap): This type defines the heap structure used for merging. It implements the heap interface, including methods for determining the heap's length, comparing elements, swapping, pushing, and popping elements.Min Heap Order: The
Lessmethod ensures that the heap is ordered based on the timestamp of the entries, with the smallest timestamp at the top. This order is crucial for deduplication, allowing the algorithm to prioritize and retain the most recent entry for each key (since the latest entries with a larger timestamp will be encountered later).
Merging and Deduplication Process: The
mergeRangesfunction performs the k-way merge, using the heap to keep track of and process the entries in order. It initializes the heap with the first element from each range and iteratively pops the minimum entry (based on timestamp). It uses a skip list (seen) to track the most recent entry for each key. If a key is encountered again with a newer timestamp, the older entry is replaced. This process continues until all entries have been processed.Handling Deletes: The algorithm also accounts for delete markers (entries indicating a key should be considered deleted). It skips adding these to the final results, ensuring that deleted keys are effectively filtered out.
Building the Result Set: After processing all entries, the algorithm iterates through the
seenlist to compile the final set of key-value pairs, excluding any deleted keys. This result set represents the merged, deduplicated range of keys requested.
Next Up
This issue marks a significant milestone in our journey, as we've successfully crafted a fully operational storage engine optimized for quick and durable writes, alongside efficient reads. We've gone deep into the sophisticated strategies for enabling efficient disk flushes that seamlessly coexist with high-priority concurrent operations like reads and writes. Moreover, we understood how to accurately query the various storage structures within the database to fulfill both point-reads and range scan requests.
In future issues, we will shift our focus to addressing write amplification. Additionally, we will explore mechanisms for crash recovery, ensuring that no data in the Memtable is lost due to crashes before they are successfully flushed to disk.
References
Designing Data intensive Applications - Martin Kleppmann
Database Internals - Alex Petrov
https://web.mit.edu/6.005/www/fa15/classes/23-locks/#:~:text=One%20way%20to%20prevent%20deadlock,order%20by%20the%20wizard's%20name.